Veilig linken naar dubieuze sites
Het schrijven van een kritisch artikel over een website van een kwakzalver of over het zoveelste gerucht over schadelijke effecten van straling of genetisch gemodifceerd voedsel, kan nauwelijks zonder een link naar die sites. Zo’n link heeft wel een belangrijk nadeel: zoekmachines als Google tellen die linkjes mee in het bepalen van de volgorde van gepresenteerde zoekresultaten. Ook een link vanaf een blog met vernietigend commentaar draagt zo bij aan de vindbaarheid van de weerlegde onzin. Dat wil je eigenlijk niet. Er zijn gelukkig wel manieren om dat te voorkomen.
In je html-code kan je met rel=”nofollow” voorkomen dat Google je link meetelt en dat gebruik ik ook zoveel mogelijk op Kloptdatwel. Maar het wordt steeds onduidelijker of dat soort afspraken ook gevolgd worden door Facebook en hoe dat werkt met ‘Likes’, en links op Twitter. Met donotlink.com houd je het in meer in eigen hand. Donotlink werkt als een URL-verkorter (zoals bit.ly bijvoorbeeld), maar zorgt dat de ‘webcrawlers’ en ‘spiders‘ van de zoekmachines die link echt niet kunnen volgen naar de ‘foute’ website. Het werkt erg eenvoudig: kopieer de link van de bewuste website en plak die in de regel op donotlink.com. Knoppie drukken en als resultaat krijg je drie mogelijkheden om veilig naar die site te verwijzen. Als je bijvoorbeeld ‘niburu.nl’ invoert, krijg je het volgende resultaat:
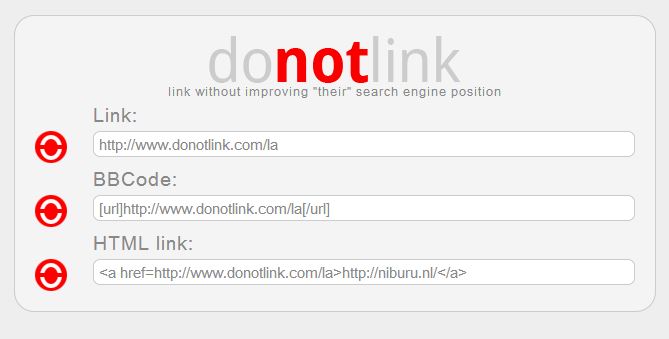
De link http://www.donotlink.com/Ia verwijst nu naar de site van niburu maar draagt niet bij aan hun pagerank. Alleen de naam van deze service is misschien een beetje ongelukkig gekozen, het leest ook een beetje als ‘niet op klikken’.
Zie ook Do Not Link allows you to ethically criticize bad content op de site van Tim Farley.
Vernieuwingen in rbutr
Om de kritische stukken, die je zelf schrijft of ergens aantreft, onder de aandacht van mede-Internetgebruikers te brengen, kun je onder andere rbutr.com gebruiken. Ruim een jaar geleden schreef ik daar al eens over en af en toe heb ik er in andere blogs naar rebuttals in het systeem van rbutr verwezen. Heel in het kort is het een database waarin twee webadressen met elkaar verbonden kunnen worden, de ene website bedoeld als weerlegging (‘rebuttal’, of hip kort ‘rbutr’) van de andere. De bedoeling van de makers van rbutr is om de beste argumenten in een bepaalde discussie vindbaar te maken voor Internetgebruikers. Het achterlaten van een link in een commentaar onder een (dubieuze) website of onder een YouTube video heeft als groot nadeel, dat die makkelijk verwijderd kunnen worden door de persoon die het oorspronkelijke stuk of video geplaatst heeft. Een kort filmpje van rbutr legt het idee uit:
Vorig jaar was het nut voor de rbutr-gebruiker nog niet zo groot. Je kon zelf wel links aanbrengen, maar de kans dat de rbutr-plugin (in Chrome) je op een rebuttal wees, die je nog niet was tegengekomen, was niet zo groot. Heel af en toe overkomt het me nu wel. De links zijn vooral handig om anderen op de bestaande (beste?) weerleggingen te wijzen als iemand weer eens een vage website op Facebook of Twitter deelt.
Intussen is het aanmaken van rebuttals een stuk makkelijker geworden. Zo kun je nu in één keer een pagina gebruiken om een heel stel andere pagina’s te ‘rebutten’. Voor de Twitter gebruikers biedt rbutr sinds kort ook een mooie uitbreiding van de mogelijkheden: als je nu op een rbutr-link kijkt, zie je meteen wie er de laatste tijd de weerlegde site heeft gedeeld en met één druk op de knop kun je via Twitter die persoon wijzen op de weerlegging(en). De nieuwe mogelijkheden komen ook aan de orde in het volgende filmpje dat het gebruik demonstreert:
Ik heb het zelf al behoorlijk wat ervaring met rbutr in combinatie met Twitter. Het is wel aan te raden om eerst even goed te kijken naar wie je zo’n tweet stuurt. Het heeft mijns inziens niet zoveel zin om een verstokte homeopaat te wijzen op de wikipedia-pagina over homeopathie (tenzij je zo iemand een beetje wil stangen, natuurlijk). Zo gauw je echter denkt dat er enig kritisch denkvermogen bij de twitteraar aanwezig is, kan het wel nut hebben. Omdat de tweets in de rbutr widget gesorteerd zijn op aantal twittervolgers kun je zien wie het meest heeft bijgedragen (al dan niet bewust) aan het verspreiden van de onzin. Met een beetje mazzel kun je zo ook in één keer een groot aantal personen bereiken als degene die je op de rebuttal wijst, jouw tweet weer retweet (voorbeeldje).
Steun Kloptdatwel
 Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
NB de rekening staat op naam van Maarten Koller, formeel eigenaar van deze site.
Plaatsing in de ‘ranking’ bij een google etc. is niet alleen afhankelijk van werkelijk bezoek.
Geografische gegevens, voorafgaand be- en gezochte pagina’s en of een
site betaald heeft voor zijn plaats in een ranking zijn daar o.a. een
van de talloze onderdeeltjes van. U ziet een ander resultaat dan dat
ik doe bij hetzelfde zoekwoord in google.
Het in staat zijn tot het ‘misleiden’ van deze rankingssystemen is maar betrekkelijk vermoed ik. Alleen al omdat tellings gegevens verwerking geen eenrichtingsweg is. De meeste sites (om het simpelte houden) houden hun eigen bezoekers aantallen bij. Deze gegevens worden door de uitbater van deze telsystemen, waaronder de site
‘eigenaar’, gebruikt voor alle mogelijke doeleinden, o.a. verkopen
aan google, bezoekersaantallen gerelateerde advertentie betalingen
etc. Daarnaast is er het hele cookie gebeuren nog waar een oneindigheid aan gegevens aan onttrokken kunnen worden.
Het verhullen van bezoek(ersaantallen) aan ‘foute’ websites is naar mijn beperkte kennis op het gebied van data analyse zo goed als onmogelijk, simpelweg om het feit dat commerciële partijen er een te groot belang bij hebben om ondanks deze trucjes toch de werkelijke waardes te weten. Omdat het van belang voor hen is dat ‘de juiste resultaten
voor deze specifieke zoekmachine gebruiker’ bovenaan staan zullen ze al 1 of meer tools klaar hebben liggen in hun arsenaal voor elke huidige of toekomstige work around. Ik zeg niet dat het geen effect heeft, ik vermoed echter dat het werkelijke effect zeer betrekkelijk
is.
Een zogenaamd dedicated opt-in systeem, in een relatief weinig gebruikte browser door middel van een ook nog eens een niet standaard geïnstalleerde plug-in voor het ranken,
beheerd door onafhankelijke partijen ,werkt in het voordeel van de beoogde doelgroep en alleen voor hen. Het zegt alleen niets over de kwaliteit van de gelinkte site. Zo zegt bijvoorbeeld het bij meer mensen bekende en enigszins vergelijkbare zogenaamde ‘like’ van facebook niets over kwaliteit. Het geeft een indicatie van hoeveel mensen (en robots en betaalde bureaus niet te vergeten) op ‘like’ geklikt hebben, niets over hoeveel mensen dat niet hebben gedaan of zelfs op ‘dislike’ zouden klikken mocht die knop bestaan. Het slimme van die ‘like’ zit er in dat men het aantal niet kan toetsen aan een openbaar bezoekersaantal.
Daarnaast kan de onafhankelijkheid van zelfs een opt-in sytseem op geen enkele manier voor ‘eeuwig’ gegarandeerd worden. Systemen gaan samen, worden verkocht, belangen kunnen veranderen.
De complexiteit van alle techniek ‘achter’ internet is haast niet meer te bevatten. En al helemaal niet voor Mien uit Assen. Door de zichzelf vermenigvuldigende structuur is
het op maandagochtend om 9 uur verzonnen, om 10 uur gebouwd en om 11
uur onderdeel van 100.000 systemen, sites en social media applicaties.
‘De waarheid’ is daardoor moeilijk met één zoekopdracht te vinden. Voorbeeld is wikipedia. Degene die het laatst in zo’n wikipedia artikel wat veranderd heeft het meest gelijk.
Zeg ik als bijna leek op website, zoekmachine en data analyse gebied.
Er is nog wel een verschil tussen de pageranking en de volgorde waarin je de zoekresultaten voorgeschoteld krijgt. Daarin speelt het profiel dat Google van je heeft opgebouwd een grote rol, maar die pagerank is het ongepersonaliseerde deel van de vergelijking, als ik dat zo mag zeggen. Je kunt ook ‘profielloos’ zoeken met Google via https://startpage.com
U begint uw verhaal met ‘de vindbaarheid van de weerlegde onzin’ in
combinatie met ‘zoekmachines als Google tellen die linkjes mee in het
bepalen van de volgorde van gepresenteerde zoekresultaten’. Vandaar
mijn wat algemene verhaal. Pagerank is tegenwoordig slechts een klein
onderdeeltje van het zoekresultaat dat google een gebruiker geeft door
inderdaad het zoekers profiel.
Pagerank (http://en.wikipedia.org/wiki/PageRank), uitgevonden door een
van de google oprichters en naamgever van de algoritme, Larry Page. En
dus niet page in de zin van (web)pagina of bladzij.
Ik vermoed dat het proberen te omzeilen weinig effect heeft.
Ik denk dat als wij niet-ingelogd gaan zoeken in Google dat de resultaten niet zo heel drastisch zullen verschillen.
In principe is het belangrijk dat je links naar je site hebt. Als die links op zich weer van een belangrijke website (KDW/Skepsis) komen telt dat goed mee. Als die links ook van sites komen die over hetzelfde onderwerp gaan, telt ook dat weer goed mee.
Dus als je op KDW linked naar een homeopatische website zal Google dat als belangrijk waarderen voor die homeopatische website want hier op KDW wordt ook veel over homeopathie geschreven. Dat dat voornamelijk negatief is, zal Google niet zien.
Volgens mij is het bezoekersaantal niet van invloed op de ranking.
En je kunt Google niet betalen voor een hoge ranking, wel andere bedrijfjes die misschien fake links gaan aanmaken, maar dat is niet zo makkelijk.
De rel=nofollow verhult geen bezoek(ersaantallen) aan die andere websites, je vertelt aan Google dat jouw website niet geaccosieerd wil worden met die link.
Misschien dat ik iets mis, maar wat is nu eigenlijk de meerwaarde van het “profielloos zoeken”, de volgorde waarin de je zoekresultaten voorgeschoteld krijgt?
Trouwens een beetje slim zoeken met Google is ook nog een hele kunst.