Een recent onderzoek kwam met een opmerkelijke conclusie: er zou een verband zijn tussen de emotionele waardering van woorden en de positie van de letters van die woorden op het QWERTY-toetsenbord. Kort samengevat: hoe meer letters van een woord aan de rechterkant van het toetsenbord zijn te vinden des te positiever wordt het woord gezien. En niet alleen in het Engels, maar ook in het Spaans en Nederlands! Als het in drie talen optreedt, kan het haast geen toeval meer zijn, toch? Of missen de onderzoekers wat alternatieve verklaringen?
 De onderzoekers Kyle Jasmin en Daniel Casasanto publiceerden in Psychonomic Bulletin & Review een artikel getiteld The QWERTY Effect: How typing shapes the meanings of words (vrij toegankelijk). Het resultaat is opvallend en het verwondert me niet dat het op allerlei websites met (populair) wetenschappelijk nieuws werd vermeld (Nederlandse sites: scientias, KIJK).
De onderzoekers Kyle Jasmin en Daniel Casasanto publiceerden in Psychonomic Bulletin & Review een artikel getiteld The QWERTY Effect: How typing shapes the meanings of words (vrij toegankelijk). Het resultaat is opvallend en het verwondert me niet dat het op allerlei websites met (populair) wetenschappelijk nieuws werd vermeld (Nederlandse sites: scientias, KIJK).
Wired sprak ook met een van de auteurs, Jasmin, en dat artikel lijkt voor veel andere publicaties weer de belangrijkste bron. Veel van de commentaren bij het Wired-artikel zijn sceptisch: gaat het hier niet om een toevallig resultaat, datafitting of iets dergelijks? Jasmin brengt daar in een commentaar tegen in dat dat bijna uitgesloten is, omdat het in alle drie de onderzochte talen optreedt:
The trend is there, demonstrated in 5 large corpora of words, which included 3 different languages. The balance of right-side and left-side letters in a word was a strong predictor of the word’s emotional valence. For every letter you add that tips the scale to the right, you get, on average, about a 4% boost in positive valence. With respect to ‘proven’ or ‘not proven’, we predicted an effect and replicated it several times — it is statistically very unlikely to be a fluke.
Wat is het verband nu precies?
De onderzoekers gebruikten een standaard Engels woordenlijst die is verrijkt met emotionele waarderingen op een 9-puntsschaal (9 heel positief, 1 heel negatief). Deze ANEW lijst heeft een Spaans (SPANEW) en Nederlands equivalent (DANEW), die gebaseerd zijn op vertalingen van de Engelse lijst en opnieuw gewaardeerd door Spaans- en Nederlandstaligen. Vervolgens definiëren de onderzoekers een score per woord die aangeeft hoe de verhouding is tussen de ‘linkse’ en ‘rechtse’ letters op het QWERTY-toetsenbord. Ze noemen die RSA (right-side advantage) en je berekent die door het totaal aantal rechtse letters (y, u, i, o, p, h, j, k, l, n, m) te verminderen met het totaal aantal linkse letters (q, w, e, r, t, a, s, d, f, g, z, x, c, y, b). Voor een woord als ‘aangenaam’ wordt de RSA dan -1-1+1-1-1+1-1-1+1 = -3.
Nu kun je kijken naar het verband tussen de RSA en de emotionele score, waarvoor ik verder de Engelse term ‘valence’ zal gebruiken zoals dat ook in het artikel gebeurt. Het volgende plaatje (uit het supplement bij het artikel, Appendix C ) laat zien wat het verband is:
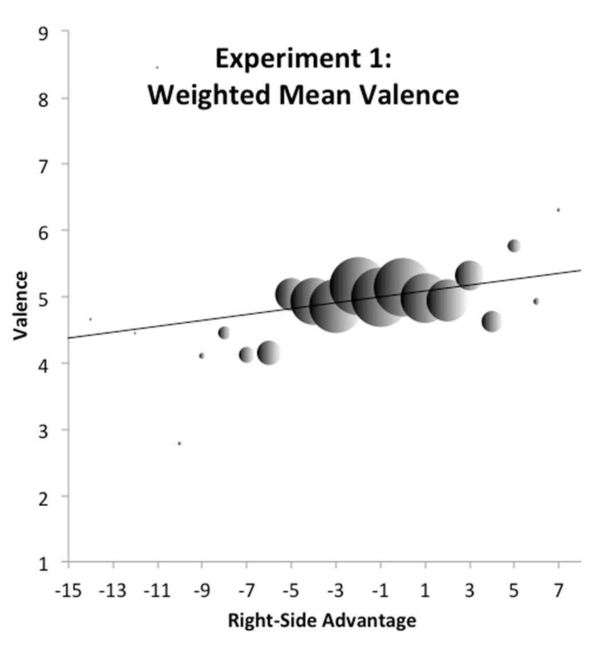
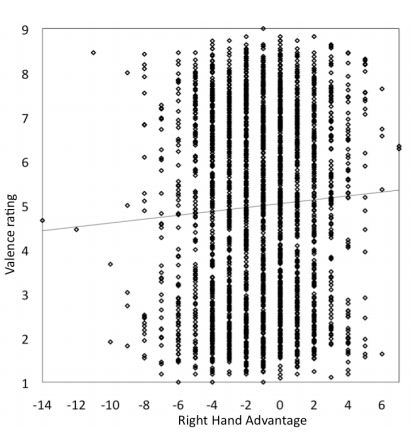
De helling van de lijn geeft het verband aan dat Jasmin in zijn quote geeft: gemiddeld geeft een stijging van een punt op de RSA-schaal een verhoging van 4% in valence. Deze grafiek is wel een beetje raar: de bollen geven het gewogen gemiddelde van de valence aan bij elke RSA. Waarom ze nu eerst dat gewogen gemiddelde bepalen en dan een regressie uitvoeren, ontgaat me een beetje. In een eerdere publicatie deden ze dat niet en zagen de plaatjes er wat chaotischer uit, maar in feite bevatten ze dezelfde informatie. Voor velen zal nu het verband er veel minder overtuigend uit zien.
De verklaring van Jasmin en Casasanto
De auteurs beweren dat het typen van ‘linkse’ letters lastiger is. Aan de linkerzijde heb je immers meer letters om uit te kiezen, wat meer moeite kost. En woorden die veel ‘linkse’ letters bevatten en aldus lastiger te typen zijn, zouden daarom ook minder positief gewaardeerd worden. In de woorden van Jasmin:
As we filter language, hundreds or thousands of words, through our fingers, we seem to be connecting the meanings of the words with the physical way they’re typed on the keyboard. If it’s easy, it tends to lend a positive meaning. If it’s harder, it can go the other way.
Natuurlijk stellen de onderzoekers dat het effect beperkt is, de betekenis van de woorden is nog altijd de belangrijkste factor die de valence bepaalt. Het klinkt nogal vergezocht, maar Jasmin stelt dat ook bekend is dat de manier waarop woorden worden uitgesproken een dergelijk invloed heeft op de betekenis van die woorden.
Is het niet gewoon toeval?
Het verband is sowieso niet al te sterk (de lijn in de grafiek loopt niet zo steil) en het zou aan de toevallige selectie van woorden in ANEW kunnen liggen (het gaat om 1043 woorden). Mark Liberman onderzocht het ook in een blog op language log. Hij deed de analyse zelf voor de ANEW en DANEW lijsten apart en dat leverde vergelijkbare grafieken op, maar het effect is dan niet significant. Dat wordt het blijkbaar pas als je de drie lijsten bij elkaar gooit op één hoop. Liberman gooide ook drie keer de koppeling tussen RSA en valence willekeurig door elkaar (met de ANEW lijst) om te kijken of het toevallig kan optreden. Hij vond één keer ongeveer hetzelfde positieve verband, één keer eerder een negatief effect en één keer geen relatie. Het zou op die gronden alleen al toeval kunnen zijn.
[update 19-3-2012] Er is intussen een discussie tussen Liberman en de auteurs gaande over onder andere de significantie. Casasanto en Jasmin hebben een officiële reactie op de kritiek op Language Log geschreven, die ook een aantal zaken in het artikel verduidelijkt: The Robustness of the QWERTY Effect.
Wat zou je verder kunnen analyseren?
Er zijn nog wel andere zaken die je zou moeten onderzoeken in mijn ogen. Als je naar de grafiek kijkt, lijkt het dat de helling van de grafiek voor een belangrijk deel bepaald wordt door de uitschieters. Beperk je de RSA-scores even tot het interval [-6,4] dan lijkt het me dat er nauwelijks een helling over zou blijven, dus geen positief verband. Het kan goed zijn dat een handjevol woorden relatief veel invloed heeft. Dit zijn dan woorden die redelijk lang zijn, anders kan er geen groot overschot aan linkse of rechtse letters zijn. Die langere woorden veranderen vaak in vertaling van Engels naar Nederlands of Spaans ook lang niet zo veel als kortere woorden, bijvoorbeeld “aggressive – agressief – agresivo” met RSA scores resp. -8,-7 en -4. De woordenlijsten zijn in mijn ogen dan ook niet zomaar als onafhankelijk te beschouwen.
De onderzoekers laten de koppeling tussen de vertaalde woorden helemaal los en hiermee gooien ze informatie weg (zonde!). Je zou die koppeling ook goed kunnen gebruiken om de hypothese te falsifiëren. Je verwacht namelijk dat de woorden in vertaling wel ongeveer vergelijkbaar blijven in valence, maar de RSA kan nogal verschillen. Als de hypothese klopt dat de RSA verband houdt met valence, zou je dat eigenlijk moeten terugzien bij die vertalingen. Als de vertaling een lagere RSA heeft, zou je ook verwachten dat het een lagere valence heeft. Dat zie je natuurlijk niet door naar enkele voorbeelden te kijken, maar het zou een zichtbaar verband moeten zijn als je dat voor alle woorden uit de ANEW lijst doet.
Een voorbeeldje dat aan de verwachting voldoet is “vomit”, dat heeft een RSA van +1 en een valence van 2,06. De Nederlandse vertaling “braaksel” heeft RSA -4 en valence 1,86. Maar “achievement”, met RSA -3 en valence 7,89, wordt “prestatie”, met RSA -5 en valence 8,17 en gaat dus net de andere kant op.
Het is een fluitje van cent om dit te doen voor alle woorden in de ANEW, DANEW en SPANEW lijsten. Maar toen ik de onderzoekers dit per e-mail voorstelde, kreeg ik een erg lauwe reactie. Ook op mijn vraag naar hun mening over de analyses van het language log reageerde Daniel Casasanto onverwacht. De analyses van Liberman zouden ‘nonsensical’ zijn, zonder overigens aan te geven waarom. Op dat moment wist ik niet eens dat Liberman een vooraanstaand hoogleraar is, maar was gewoon erg overtuigd van zijn argumenten in zijn blog en de commentaren erop.
Ik zou de analyse naar de invloed van de mogelijke afhankelijkheid tussen de lijsten graag zelf even doen, maar ik vond ze alleen gealfabetiseerd en de koppeling tussen origineel en vertaling zou je zelf moeten reconstrueren. Het is wel te doen, maar het kost behoorlijk wat tijd. Ik verwacht eerlijk gezegd ook niet dat het verband er uit zal komen, dus die klus ga ik vooralsnog niet op me nemen.
[update 19-3-2012] Uit de nadere toelichting van Casanato en Jasmin maak ik op dat ze de mogelijke afhankelijkheid tussen de verschillende vertalingen hebben proberen te ondervangen door in de regressie de valence van de vertalingen als ‘herhaalde waarnemingen’ in te voeren. Ik vraag me af of dit juist is, want dan ga er a-priori van uit dat de werkelijke valence in elke taal hetzelfde zou moeten zijn en dat is duidelijk niet het geval. Je zou het bij een correcte vertaling wel verwachten, maar zo simpel is het niet: als je een woord als ‘execution’ in het Nederlands vertaald als ‘uitvoering’ mis je de negatieve connotatie van ‘terechtstelling’.

Het nevenbewijs van de onderzoekers
Naast het hoofdexperiment keken de onderzoekers naar twee andere lijstjes (dat maakt samen met de drie eerder genoemde lijsten het totaal van vijf uit de quote van Jasmin). Ten eerste analyseerden ze een woordenlijst met woorden die na de ontwikkeling van het QWERTY-toetsenbord zijn ontstaan (dus na 1873). Het idee daarachter is dat je dan zou kunnen zien of met de vastlegging van de toetsenindeling ook de ontwikkeling van nieuwe woorden beïnvloed zou worden. En weer bleek hetzelfde verband.
Nu is het gebruikte lijstje van 63 woorden niet op een heel erg duidelijke manier samengesteld (zie het supplement voor de hele lijst) en overtuigt mij daarom niet echt. Veel woorden zijn populair internetjargon, niet echt ‘common knowledge’ en veel zijn ook min of meer dubbel.
Ten slotte werd er onderzocht hoe het met de valence van fantasiewoorden zit. Met een algoritme werd een lijstje woorden samengesteld en via Mechanical Turk op Internet aan proefpersonen voorgelegd. Weer eenzelfde verband. Ook dit experiment stelt in mijn ogen niet veel voor. Door de vorm van de gebruikte woorden is de lijst niet echt vergelijkbaar met een lijst ‘echte’ woorden (de variatie in woordlengte is bijvoorbeeld heel beperkt). En het zijn dan wel niet bestaande Engelse woorden, sommige komen bijvoorbeeld weer wel in het Nederlands voor. Belangrijker is echter de vraag of het gevoel bij een niet-bestaand woord wel vergeleken kan worden met het gevoel van een woord waarvan de betekenis bekend verondersteld mag worden.
Kortom: als er al sprake is van een QWERTY-effect, dan overtuigt deze studie mij daar niet van. Misschien dat de onderzoekers in een vervolg meteen ook even de invloed van de kleur van de tekst mee kunnen nemen, of het lettertype?