Een recent onderzoek kwam met een opmerkelijke conclusie: er zou een verband zijn tussen de emotionele waardering van woorden en de positie van de letters van die woorden op het QWERTY-toetsenbord. Kort samengevat: hoe meer letters van een woord aan de rechterkant van het toetsenbord zijn te vinden des te positiever wordt het woord gezien. En niet alleen in het Engels, maar ook in het Spaans en Nederlands! Als het in drie talen optreedt, kan het haast geen toeval meer zijn, toch? Of missen de onderzoekers wat alternatieve verklaringen?
 De onderzoekers Kyle Jasmin en Daniel Casasanto publiceerden in Psychonomic Bulletin & Review een artikel getiteld The QWERTY Effect: How typing shapes the meanings of words (vrij toegankelijk). Het resultaat is opvallend en het verwondert me niet dat het op allerlei websites met (populair) wetenschappelijk nieuws werd vermeld (Nederlandse sites: scientias, KIJK).
De onderzoekers Kyle Jasmin en Daniel Casasanto publiceerden in Psychonomic Bulletin & Review een artikel getiteld The QWERTY Effect: How typing shapes the meanings of words (vrij toegankelijk). Het resultaat is opvallend en het verwondert me niet dat het op allerlei websites met (populair) wetenschappelijk nieuws werd vermeld (Nederlandse sites: scientias, KIJK).
Wired sprak ook met een van de auteurs, Jasmin, en dat artikel lijkt voor veel andere publicaties weer de belangrijkste bron. Veel van de commentaren bij het Wired-artikel zijn sceptisch: gaat het hier niet om een toevallig resultaat, datafitting of iets dergelijks? Jasmin brengt daar in een commentaar tegen in dat dat bijna uitgesloten is, omdat het in alle drie de onderzochte talen optreedt:
The trend is there, demonstrated in 5 large corpora of words, which included 3 different languages. The balance of right-side and left-side letters in a word was a strong predictor of the word’s emotional valence. For every letter you add that tips the scale to the right, you get, on average, about a 4% boost in positive valence. With respect to ‘proven’ or ‘not proven’, we predicted an effect and replicated it several times — it is statistically very unlikely to be a fluke.
Wat is het verband nu precies?
De onderzoekers gebruikten een standaard Engels woordenlijst die is verrijkt met emotionele waarderingen op een 9-puntsschaal (9 heel positief, 1 heel negatief). Deze ANEW lijst heeft een Spaans (SPANEW) en Nederlands equivalent (DANEW), die gebaseerd zijn op vertalingen van de Engelse lijst en opnieuw gewaardeerd door Spaans- en Nederlandstaligen. Vervolgens definiëren de onderzoekers een score per woord die aangeeft hoe de verhouding is tussen de ‘linkse’ en ‘rechtse’ letters op het QWERTY-toetsenbord. Ze noemen die RSA (right-side advantage) en je berekent die door het totaal aantal rechtse letters (y, u, i, o, p, h, j, k, l, n, m) te verminderen met het totaal aantal linkse letters (q, w, e, r, t, a, s, d, f, g, z, x, c, y, b). Voor een woord als ‘aangenaam’ wordt de RSA dan -1-1+1-1-1+1-1-1+1 = -3.
Nu kun je kijken naar het verband tussen de RSA en de emotionele score, waarvoor ik verder de Engelse term ‘valence’ zal gebruiken zoals dat ook in het artikel gebeurt. Het volgende plaatje (uit het supplement bij het artikel, Appendix C ) laat zien wat het verband is:
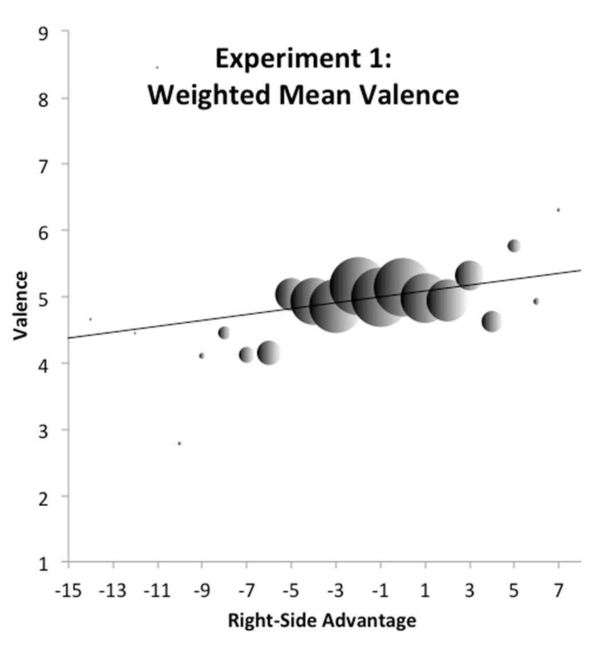
De helling van de lijn geeft het verband aan dat Jasmin in zijn quote geeft: gemiddeld geeft een stijging van een punt op de RSA-schaal een verhoging van 4% in valence. Deze grafiek is wel een beetje raar: de bollen geven het gewogen gemiddelde van de valence aan bij elke RSA. Waarom ze nu eerst dat gewogen gemiddelde bepalen en dan een regressie uitvoeren, ontgaat me een beetje. In een eerdere publicatie deden ze dat niet en zagen de plaatjes er wat chaotischer uit, maar in feite bevatten ze dezelfde informatie. Voor velen zal nu het verband er veel minder overtuigend uit zien.
De verklaring van Jasmin en Casasanto
De auteurs beweren dat het typen van ‘linkse’ letters lastiger is. Aan de linkerzijde heb je immers meer letters om uit te kiezen, wat meer moeite kost. En woorden die veel ‘linkse’ letters bevatten en aldus lastiger te typen zijn, zouden daarom ook minder positief gewaardeerd worden. In de woorden van Jasmin:
As we filter language, hundreds or thousands of words, through our fingers, we seem to be connecting the meanings of the words with the physical way they’re typed on the keyboard. If it’s easy, it tends to lend a positive meaning. If it’s harder, it can go the other way.
Natuurlijk stellen de onderzoekers dat het effect beperkt is, de betekenis van de woorden is nog altijd de belangrijkste factor die de valence bepaalt. Het klinkt nogal vergezocht, maar Jasmin stelt dat ook bekend is dat de manier waarop woorden worden uitgesproken een dergelijk invloed heeft op de betekenis van die woorden.
Is het niet gewoon toeval?
Het verband is sowieso niet al te sterk (de lijn in de grafiek loopt niet zo steil) en het zou aan de toevallige selectie van woorden in ANEW kunnen liggen (het gaat om 1043 woorden). Mark Liberman onderzocht het ook in een blog op language log. Hij deed de analyse zelf voor de ANEW en DANEW lijsten apart en dat leverde vergelijkbare grafieken op, maar het effect is dan niet significant. Dat wordt het blijkbaar pas als je de drie lijsten bij elkaar gooit op één hoop. Liberman gooide ook drie keer de koppeling tussen RSA en valence willekeurig door elkaar (met de ANEW lijst) om te kijken of het toevallig kan optreden. Hij vond één keer ongeveer hetzelfde positieve verband, één keer eerder een negatief effect en één keer geen relatie. Het zou op die gronden alleen al toeval kunnen zijn.
[update 19-3-2012] Er is intussen een discussie tussen Liberman en de auteurs gaande over onder andere de significantie. Casasanto en Jasmin hebben een officiële reactie op de kritiek op Language Log geschreven, die ook een aantal zaken in het artikel verduidelijkt: The Robustness of the QWERTY Effect.
Wat zou je verder kunnen analyseren?
Er zijn nog wel andere zaken die je zou moeten onderzoeken in mijn ogen. Als je naar de grafiek kijkt, lijkt het dat de helling van de grafiek voor een belangrijk deel bepaald wordt door de uitschieters. Beperk je de RSA-scores even tot het interval [-6,4] dan lijkt het me dat er nauwelijks een helling over zou blijven, dus geen positief verband. Het kan goed zijn dat een handjevol woorden relatief veel invloed heeft. Dit zijn dan woorden die redelijk lang zijn, anders kan er geen groot overschot aan linkse of rechtse letters zijn. Die langere woorden veranderen vaak in vertaling van Engels naar Nederlands of Spaans ook lang niet zo veel als kortere woorden, bijvoorbeeld “aggressive – agressief – agresivo” met RSA scores resp. -8,-7 en -4. De woordenlijsten zijn in mijn ogen dan ook niet zomaar als onafhankelijk te beschouwen.
De onderzoekers laten de koppeling tussen de vertaalde woorden helemaal los en hiermee gooien ze informatie weg (zonde!). Je zou die koppeling ook goed kunnen gebruiken om de hypothese te falsifiëren. Je verwacht namelijk dat de woorden in vertaling wel ongeveer vergelijkbaar blijven in valence, maar de RSA kan nogal verschillen. Als de hypothese klopt dat de RSA verband houdt met valence, zou je dat eigenlijk moeten terugzien bij die vertalingen. Als de vertaling een lagere RSA heeft, zou je ook verwachten dat het een lagere valence heeft. Dat zie je natuurlijk niet door naar enkele voorbeelden te kijken, maar het zou een zichtbaar verband moeten zijn als je dat voor alle woorden uit de ANEW lijst doet.
Een voorbeeldje dat aan de verwachting voldoet is “vomit”, dat heeft een RSA van +1 en een valence van 2,06. De Nederlandse vertaling “braaksel” heeft RSA -4 en valence 1,86. Maar “achievement”, met RSA -3 en valence 7,89, wordt “prestatie”, met RSA -5 en valence 8,17 en gaat dus net de andere kant op.
Het is een fluitje van cent om dit te doen voor alle woorden in de ANEW, DANEW en SPANEW lijsten. Maar toen ik de onderzoekers dit per e-mail voorstelde, kreeg ik een erg lauwe reactie. Ook op mijn vraag naar hun mening over de analyses van het language log reageerde Daniel Casasanto onverwacht. De analyses van Liberman zouden ‘nonsensical’ zijn, zonder overigens aan te geven waarom. Op dat moment wist ik niet eens dat Liberman een vooraanstaand hoogleraar is, maar was gewoon erg overtuigd van zijn argumenten in zijn blog en de commentaren erop.
Ik zou de analyse naar de invloed van de mogelijke afhankelijkheid tussen de lijsten graag zelf even doen, maar ik vond ze alleen gealfabetiseerd en de koppeling tussen origineel en vertaling zou je zelf moeten reconstrueren. Het is wel te doen, maar het kost behoorlijk wat tijd. Ik verwacht eerlijk gezegd ook niet dat het verband er uit zal komen, dus die klus ga ik vooralsnog niet op me nemen.
[update 19-3-2012] Uit de nadere toelichting van Casanato en Jasmin maak ik op dat ze de mogelijke afhankelijkheid tussen de verschillende vertalingen hebben proberen te ondervangen door in de regressie de valence van de vertalingen als ‘herhaalde waarnemingen’ in te voeren. Ik vraag me af of dit juist is, want dan ga er a-priori van uit dat de werkelijke valence in elke taal hetzelfde zou moeten zijn en dat is duidelijk niet het geval. Je zou het bij een correcte vertaling wel verwachten, maar zo simpel is het niet: als je een woord als ‘execution’ in het Nederlands vertaald als ‘uitvoering’ mis je de negatieve connotatie van ‘terechtstelling’.

Het nevenbewijs van de onderzoekers
Naast het hoofdexperiment keken de onderzoekers naar twee andere lijstjes (dat maakt samen met de drie eerder genoemde lijsten het totaal van vijf uit de quote van Jasmin). Ten eerste analyseerden ze een woordenlijst met woorden die na de ontwikkeling van het QWERTY-toetsenbord zijn ontstaan (dus na 1873). Het idee daarachter is dat je dan zou kunnen zien of met de vastlegging van de toetsenindeling ook de ontwikkeling van nieuwe woorden beïnvloed zou worden. En weer bleek hetzelfde verband.
Nu is het gebruikte lijstje van 63 woorden niet op een heel erg duidelijke manier samengesteld (zie het supplement voor de hele lijst) en overtuigt mij daarom niet echt. Veel woorden zijn populair internetjargon, niet echt ‘common knowledge’ en veel zijn ook min of meer dubbel.
Ten slotte werd er onderzocht hoe het met de valence van fantasiewoorden zit. Met een algoritme werd een lijstje woorden samengesteld en via Mechanical Turk op Internet aan proefpersonen voorgelegd. Weer eenzelfde verband. Ook dit experiment stelt in mijn ogen niet veel voor. Door de vorm van de gebruikte woorden is de lijst niet echt vergelijkbaar met een lijst ‘echte’ woorden (de variatie in woordlengte is bijvoorbeeld heel beperkt). En het zijn dan wel niet bestaande Engelse woorden, sommige komen bijvoorbeeld weer wel in het Nederlands voor. Belangrijker is echter de vraag of het gevoel bij een niet-bestaand woord wel vergeleken kan worden met het gevoel van een woord waarvan de betekenis bekend verondersteld mag worden.
Kortom: als er al sprake is van een QWERTY-effect, dan overtuigt deze studie mij daar niet van. Misschien dat de onderzoekers in een vervolg meteen ook even de invloed van de kleur van de tekst mee kunnen nemen, of het lettertype?
Steun Kloptdatwel
 Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
NB de rekening staat op naam van Maarten Koller, formeel eigenaar van deze site.
Als de verklaring voor het (omstreden) effect is dat linkse letters moeilijker te typen zijn, verwacht ik ook dat links- of rechtshandigheid invloed heeft op het effect.
Dat werd wel bekeken door de onderzoekers. Bij het normeren van de Nederlandse vertaling hebben ze de proefpersonen aan laten geven of ze rechts – of linkshandig waren. Het ‘effect’ was echter hetzelfde, maar niet significant vanwege het lage aantal linkshandigen in de groep.
Ergens las ik nog dat de auteurs ook niet verwacht hadden dat het bij linkshandigen precies omgekeerd zou zijn, omdat de gevoelswaarde van de woorden voor het grootste deel bepaald wordt door rechtshandigen (90%). Linkshandigen zouden zich aansluiten bij het ‘oordeel’ van de meerderheid. Beetje vaag allemaal, wat mij betreft.
Dat vind ik heel gek; zeggen die linkshandigen (waaronder mijzelf) dat dan alleen maar omdat al die rechtshandigen het zeggen? Van mezelf kan ik me dat eigenlijk niet voorstellen. En dan is het voor hen toch geen gevoelswaarde maar gewoon napraten? Ik vind dit zo’n ongrijpbaar onderzoekje dat ik er helemaal iebel van word. Maar dat komt wellicht omdat ik ook niet veel snap van de statistiek, want ik zie eigenlijk niet wat er zou zijn aangetoond.
Wij hebben thuis een woordenboom. Daar plakken we post-itjes op met woorden die we leuk, wonderlijk, bijzonder, mooi of heel erg grappig vinden, in het Nederlands en ook in andere talen. Ik ga eens kijken hoe het daar zit met het QWERTY-effect – en handigheid, want ik ben de enige linkshandige bij ons thuis.
Een mogelijke ‘verklaring’ is sommige klanken inderdaad statistisch samenhangen met een positieve gevoelswaarde. Laten we zeggen dat dat de klinkers zijn. Rechts zijn er drie klinkers en links twee. Dan zou het effect ‘veroorzaakt’ zijn door de asymmetrische verdeling van die paar letters over links/rechts.
Als je goed kijkt staat y zowel links als rechts, dus precies dit argument klopt niet. Maar het zou iets anders kunnen zijn. Het effect is (als je naar die ‘grafiek uit eerder artikel’ kijkt) zo miniem dat je wel heel erg zeker moet zijn dat je geen subtiele bias meet.
De these dat de negatieve connotatie van een woord wordt veroorzaakt door het tikken met linker- of rechterhand is wel erg fantastisch. De proef van Liberman die keek met random herkoppelingen is veel overtuigender. Maar ik snap niet dat hij dat maar een paar keer deed. Dat kan toch makkelijk automatisch duizenden malen gedaan worden? Dan krijg je een experimenteel bepaalde verdeling van de helling van de regressielijn, en dan kun je op basis daarvan zeggen hoe bijzonder de gevonden helling is.
Proberen de significatie van de helling (die zag ik niet staan) theoretisch te berekenen is hachelijk, want je weet eigenlijk de theoretische verdeling niet. ‘Enigzins normaal’ is niet goed genoeg, vanwege het feit dat de paar uitbijters het beeld lijken te bepalen.
Zeer interessant, met name ook de reacties op je vragen en de kritiekloze publicaties. En jammer (maar wel begrijpelijk) dat je de conclusie trekt dat eigen onderzoek relatief weinig perspectief heeft. Op die manier wordt zo’n resultaat nooit weersproken.
Overigens gebruiken steeds meer mensen spraak naar tekst programmatuur, ik doe dit zelf ook. Je spreekt tegen je computer die het gesprokene omzet in tekst. Het werkt veel sneller en foutlozer. Onder die groep zou het effect moeten verdwijnen. Zou je dan parallelle subculturen krijgen?
Ik snapte weinig van de reactie van Casasanto: waarom wel de moeite nemen om te reageren, maar dan helemaal niet in te gaan op mijn vragen en voorstellen? Bij zijn laatste antwoord, mailde hij nota bene het artikel als bijlage, alsof ik dat niet nog gelezen had … Hij beweerde dat mijn bedenkingen waren meegenomen in het artikel, maar dan heb ik het blijkbaar niet goed gelezen. Ik trof in ieder geval niets aan van een soort covariantie-analyse tussen de gebruikte lijsten.
Dit lijkt me een typisch gevalletje van “statistisch significant betekent nog geen relevant” effect. Het maximale verschil tussen de minimale en maximale score is krap 1 punt. Op een 9-punts schaal is dat niet relevant.
Ik kan een sterker verband vinden tussen het aantal geboortes en de ooievaarspopulatie in Nederland.
Overigens was het artikel voor mij wel degelijk leerzaam: ik heb er nooit bij stilgestaan dat er voor de linkerhand meer letters beschikbaar waren dan voor de rechterhand (hier wreekt het ontbreken van een typdiploma zich).
Om dat effect uit te schakelen zou je verwachten dat de auteurs evenveel “linkse” als “rechtse” woorden hadden geselecteerd.
Een ander puntje dat ik ook aan de auteurs had voorgelegd is het volgende: zelf type ik bijvoorbeeld de ‘b’ vaak met rechts en ik vroeg ze of het veel zou uitmaken als je de ‘b’ bij de rechtse letters zou indelen of helemaal buiten beschouwing zou laten. Maar dat was alleen maar ‘ruis’, kreeg ik gemaild. Toch jammer, het had de RSA van een woord als ‘allerbelabberst’ toch een mooie boost kunnen geven.
Moet je de b eigenlijk niet met de rechterhand typen? Ik heb ook geen typediploma, maar het lijkt mij het gemakkelijkst en ik ben linkshandig.
Volgens het blind type systeem valt de ‘b’ onder de linkerwijsvinger:
http://en.wikipedia.org/wiki/Touch_typing Ook bij die ergonomische toetsenborden, waar het toetsenbord in het midden gesplitst is, valt de ‘b’ aan de linkerkant.
Sorry Pepijn, ik heb links en rechts weer eens verwisseld. Ik haal ze wel vaker door elkaar. Ik type de b dus met m’n linkerhand.
Overigens, het woord kul kan je geheel met je rechterhand typen. Dat moet dus een positieve uitstraling hebben. Het is ongeveer het eerste woord dat me te binnen schiet bij het lezen van dit onderzoek.
Reactie verwijderd.
Wat een vreemd antwoord, “ruis”; wat voor ruis is dat dan? Moet er trouwens geen d voor de t van dat allerbelabberdst moeilijke woord?
je hebt gelijk: http://apps.nrc.nl/stijlboek/allerbelabberdst-allerbelabberst en dat van die ruis begrijp ik ook niet, hoor! Hij schreef letterlijk “The letters on the edge are a source of noise — we find the QWERTY effect in spite of this”
Maar klopt het dan al wel? Want als er meer letter beschikbaar zijn, zijn er toch ook meer woorden én meer soorten woorden (meer verschillende gevoelswaarden) mogelijk met links? Of denk ik nou heel stom?
Wat wel bekend is dat het ‘QWERTY’ toetsenbord ouderwets is en allang beter kan. 100 jaar geleden was het namelijk nog stoer als je als verkoper het woord ‘typewriter’ in 1 zin kon typen. (doe maar eens).
De reden dat de letters zo geplaatst zijn op het toetsenbord is vanwege het feit dat met snel typen, vroeger de linten in elkaar verstrengeld zouden raken.
Is tegenwoordig natuurlijk allang niet meer zo.
Niet de linten, want een schrijfmachine heeft maar 1 lint. Het waren de hamertjes.
O, dat wist ik niet, grappig.
“Ik heb een mooie typewriter.” Voila, zo moeilijk was het niet on het woord ‘typewriter’ in een zin te typen 😉
Ik denk dat Thomas een iets te snelle vertaling gaf van een zin als “the letters forming the word TYPEWRITER are all on the same line”. ‘line’ moet hier zijn ‘rij’ en niet ‘zin’. Google maar eens op ‘qwerty typewriter line’ dan zie je diverse sites die als bron gebruikt kunnen zijn.
Overigens vond ik net een heel interessant artikel over de geschiedenis van het QWERTY toetsenbord: http://kanji.zinbun.kyoto-u.ac.jp/~yasuoka/publications/PreQWERTY.html
De auteurs geven een heel andere verklaring voor de indeling die niets te maken heeft met de ‘hamertjes’-, noch met de ‘typewriter’-theorie. Het zou samenhangen met het eerste voornamelijke gebruik, nl door telegrafisten die morseberichten ontvingen. Moet het nog nauwkeurig lezen, maar het maakte een goede eerste indruk.
HEUS NIET
@pjvanerp:disqus
Wat een rare mededeling, ik snap er niks van. Bedoelen ze dat ze een qwerty-effect vinden zonder letters? En wat bedoelen ze met “letters on the edge”? Alle letters aan alle randen? Dan blijven er niet veel over. Dus ze zullen wel de onderste rand bedoelen, maar dat scheelt ook al veel letters, zoals de vriendelijke b, de vrolijke v en de lieve m, van bijvoorbeeld mama. Tellen dan alleen die twee a’s van mama dan maar mee? Maar dat is helemaal geen woord meer, dus hoe kan er dan toch sprake zijn van een qwerty-effect? Nou ja, dat is dan zeker dat “in spite of this”. In spite of there being no letters is er toch een qwerty-effect. Of zoiets. Mysterieus.
Ik begrijp er helemaal niets van.
Ik denk dat ze bedoelen “aan de rand van het links/rechts gebied”.
Als ze het echt mooi hadden willen doen, hadden ze van elke letter een verdeling vastgesteld hoe vaak die links/rechts/even vaak wordt aangeraakt door de linker/rechter hand. Dan de ‘right hand advantage’ inclusief verdeling voor elk geselecteerd woord bepalen en daarna de de ‘valence’ bepalen. Op die manier zul je er zeer waarschijnlijk achter komen dat er inderdaad geen QWERTY-effect bestaat.
En @Thomas: Ook al heeft de qwerty-indeling geen technische functie meer, is het wel prettig dat er een bepaalde standaard is. Ik typ in Frankrijk wel eens op een AZERTY-toetsenbord (de Franse standaard)…..alsof je instantaan woordblind bent geworden!
De reactie van de onderzoekers ging over de b en met welke vinger je die typt, of dat wat uitmaakt. Ik begrijp uit hun reactie niet dat het om letters aan de zijkant gaat bij die ruis. Maar als dat wel zo is blijven er niet veel letters over want de b zit ook in het ruisgebied. Maar goed, ook in de ruis schijnt het qwerty-effect gevonden te worden.
??
Mark Liberman deed de analyse nog eens met een veel grotere dataset (bijna 10.000 woorden) en daaruit bleek … geen verband.
http://languagelog.ldc.upenn.edu/nll/?p=3837
http://languagelog.ldc.upenn.edu/myl/HEDO1.png ”
The slope of the fitted regression line is -0.0008636 ± 0.0044066 “Ben echter bang dat deze nieuwe mythe net zo hardnekkig zal blijken te zijn als dat ‘typewriter’-verhaal.
Volgens scientias.nl komt Casasanto binnenkort met een officiële reactie op de analyse van Liberman
http://www.scientias.nl/typen-heeft-invloed-op-betekenis-woorden/57746 Inhoudelijk is er nog niet meer bekend over die kritiek dan het volgende:
Die kritiek gaat nog niet in op Libermans update, waarin hij een grotere lijst gebruikte en ook geen relatie vond. De QWERTY-controverse gaat verder!
Casasanto en Jasmin hebben een officiële reactie gepubliceerd op de kritiek van met name Liberman: The Robustness of the QWERTY Effect. Zij hebben zelf voor alle woordenlijsten die random herkoppelingen tussen RSA en Valence in veelvoud uitgevoerd en dan blijkt de gevonden relatie toch opvallend. Die is niet significant voor alle lijsten apart, maar samengevoegd zou het dus nog steeds wel significant zijn. Nu ook in het Portugees! Daarom stellen ze dat het wel degelijk om een ‘robuust effect’ gaat. Ook de grotere woordenlijst die Liberman gebruikte zou bij juiste weging van woordlengte en letterfrequentie een positief verband laten zien.
Mark Liberman heeft intussen ook daarop weer een commentaar gegeven: Response to Jasmin and Casasanto’s reponse to me en zo gaat de discussie lekker verder.
Ik begrijp uit het verhaal van Casasanto en Jasmin overigens dat ze wel rekening hebben gehouden met een mogelijke afhankelijkheid tussen de verschillende vertalingen van de ANEW-lijst. In het oorspronkelijke artikel was dat een beetje cryptisch vermeld. In de regressie hebben ze de vertalingen als ‘herhaalde’ waarnemingen ingevoerd:
Dit roept bij mij wel de vraag op of de regressie eigenlijk niet veel ingewikkelder zou moeten zijn dan tot nu toe is uitgevoerd. Casasanto, Jasmin, maar ook Liberman nemen zo te zien de waarden voor valence als exact op in het model. Dat is echter niet juist, omdat het gemiddelden zijn van observaties van de proefpersonen. Om het helemaal correct te doen, moet je dus eigenlijk alle losse waarderingen invoeren (en misschien nog rekening houden met het feit dat de proefpersonen niet alle woorden hebben gezien). Of dat wat uitmaakt voor de relatie, betwijfel ik, maar het kan wel iets betekenen voor de significantie.
Wellicht dat er nog een vervolgreactie op mijn toevoeging komt, en het is die waar ik enigszins nieuwsgierig naar ben, want ik heb een paar andere vragen mbt. dit onderzoek waarvan de onderzoekers zich op voorhand rekenschap van hadden kunnen geven.
Ik geef me er rekenschap van dat deze reactie mosterd is na een maaltijd die reeds sinds lang door de rioolzuivering heen is gegaan en het restafval is omgezet tot kunstmest en verworden tot een smakelijke maalijd..
Ten eerste is de onderwerpskeuze zo arbitrair dat ik me met een goed gemoed afvraag of de onderzoekers bij zichzelf hebben afgevraagd of ze uberhaupt enig idee hadden of dit niet zou uitmonden in een oceaan van kletspraat. Sorry, maar dit onderzoek wekt geen enkele andere indruk.
Ga ik het serieus nemen, dan heb ik een paar andere vragen.
Waarom uitsluitend losse woorden? Waarom niet 100 zelfmoordbrieven en 100 liefdesbrieven als uitgangspunt genomen. Als het om de woordkeuze gaat. Volgende vraag.
Er lijkt op voorhand uit te worden gegaan dat iedereen, of op zijn minst een significant deel van de mensheid, heeft leren typen op de door de typecursus voorgeschreven manier, terwijl ik geloof het overgrote deel net als mij het tamelijk bevredigend doet met slechts 2 vingers, en driekwart van het klavier bespeel met mijn rechterhand. Daar zit wat professionele deformatie bij, omdat ik vaak met links de alt vasthoud om de cijfers in te tikken op het nummerieke deel voor de accenten alsdat ik vaak te kampen heb met de franse taal, en een azerty-keyboard niet behulpzaam is om in 3 talen te schrijven.
Vandaaruit ga ik verder. Ervanuitgaande dat de muishand nog steeds bestaat, heb ik vaak een enorme pijn in mijn rechterpols, die soms opkruipt tot mijn elleboog. Vanuit dat perspectief bezien zou ik dus naar eerder genoemde verhouding een hekel moeten hebben aan driekwart van alle woorden, omdat ik die invoer met pijn.
De BS-meter staat nu voorbij het rood. Het draadje van de spoel begint te roken.
Ik zit -zoals U correct geraden heeft- acher een computer met heel wat meer mogelijkheden dan de middeleeuwse schrijfmachine wat betreft invoer. En vaak maak ik gebruik van short-cuts zoals ctrl-i voor het scheeftrappen van de tekst voor een accent, en zo zijn er nog een heleboel, teveel om op te noemen. Mijn handen zwerven over het toetsenbord, ik ben niet bezig met het invoeren van ‘positieve’ of ‘negatieve’ connotaties, ik ben bezig met het invoeren van tekst die ik ter plekke verzin. Wat mijn handen daarbij doen is van ondergeschikt belang. En daarbij kom ik bij een ander onderscheid, namelijk dat van het geestelijke leven en dat van het biologische. Er lijkt mij een wezenlijk verschil tussen het schoppen tegen een bal (voor de lol, of, in extremo, om mijn spieren te trainen) en dat van de deur van de baas (ik ben het ergens in extremo niet mee eens) terwijl het in beide gevallen gaat om dezelfde handeling. Een verwarring van de abstractie met het concrete. Zoals dat een schilderij ongeveer €10,- waard is als het aankomt op pigment en doek, en €100.000.000,- omdat het door Van Gogh is gemaakt. (Materieel versus immaterieel). What is it these people are trying to establisch?
Ik heb te kampen met een toetsenbord waarmee de invoer van betekenis arbitrair tot stand is gekomen. Ik zou zeggen, dat is de eerste vraag die men had kunnen stellen: wat is het mogelijke resultaat van een onderzoek naar iets dat een willekeurige of onbepaalde basis heeft, met een nogal onbepaalde set van uitgangsdata met een beperkte omvang, en dat dan weer gegoten over arbitrair bepaald gedrag (hoe gebruikt een willekeurig individu zijn toetsenbord). Naast nog de verwarring van de sferen van existentie. Men heeft iets proberen uit te filteren van een laag chaos ondergedompeld onder chaos overgoten met een saus van chaos waarbij men en passent in de war raakte tijdens het proces van ontwarring en daarbij het zicht heeft verloren in een sneeuwstorm van betekenissen.
Dat is geloof ik dan weer het rijk van de semantiek. Wat een vorm van kunst is die naast die van de statistiek vaak onbekend zijn aan elkaar, omdat de een de taalkunde betreft, en de andere de wiskunde.
Ik zou ze graag eens romantische avond aanbieden om elkaar eens echt te leren kennen. Bij een glas wijn en een kaarsje.
Het is betekenisloos rommelonderzoek met een enorme kostprijs. Op voorhand. Dat is het wat het op mij de indruk wekt. En ik geloof dat het met de door mij aangedragen argumenten ook als dusdanig afgedaan kan worden. Mocht er echter iemand zijn die mij hierop op scherp willen stellen, dan hoor ik dat graag.