Sinds enige tijd schrijft Victor Lamme, hoogleraar Cognitieve Neurowetenschap aan de Universiteit van Amsterdam, columns in de krant nrc.next. Op 16 maart publiceerde hij er een met de titel ‘De pedoscan‘. Die is gewijd aan het onderzoek van Jorge Ponseti waarin die bekijkt of je met hersenscans onderscheid kunt maken tussen pedofielen en ‘normale’ mensen. Opmerkelijke conclusie van dat onderzoek is dat dat vrij precies mogelijk lijkt te zijn. Ponseti ontwikkelde een test waarin proefpersonen werden blootgesteld aan plaatjes van naakte volwassenen en kinderen. En door te kijken hoe verschillend de scans eruit zien, kan met een hoop rekenwerk ‘bepaald’ worden of iemand pedofiel dan wel ‘normaal’ is. Maar dit soort rekenpartijen op basis van meetgegevens hebben toch altijd te maken met marges, fout-positieven en dat soort statistische kanttekeningen? Hoe zit het daar mee? Victor Lamme trekt in ieder geval niet de goede conclusies uit het gecijfer. Een 100 procent betrouwbare pedoscan ligt nog niet om de hoek.

Bij zo’n beetje elke test die twee uitslagen geeft, positief of negatief, heb je naast de correcte (positieve en negatieve) uitslagen ook fout-negatieve en fout-positieve uitslagen. Een fout-negatieve uitslag wil zeggen dat je test de eigenschap niet aanwijst, terwijl die er in werkelijkheid wel is. Een fout-positieve uitslag is net andersom: de eigenschap wordt ten onrechte aangetoond door de test.
Nu wil je graag dat een test zo weinig mogelijk fout-negatieve resultaten geeft, dat heb je een hoge sensitiviteit, maar ook zo weinig mogelijk fout-positieve, een hoge specificiteit. Meestal is het lastig om zowel de sensitiviteit als de specificiteit heel hoog te krijgen. Vooral in juridische aangelegenheden is een hoge specificiteit van belang, je wil immers niet mensen ten onrechte beschuldigen.
Hoe betrouwbaar is de ‘pedoscan’?
De resultaten van Ponseti zijn zo mooi, omdat zijn test de hersenscans van de 32 ‘normale’ proefpersonen allemaal als ‘normaal’ herkende, een specificiteit van 100 procent! Op de sensitiveit moet dan wel wat ingeleverd worden, want van de 24 pedofielen, werden er 3 niet juist geïdentificeerd. De sensitiviteit is dus 21/24 = 88 procent, afgerond. Lamme legt uit waarom het zo belangrijk is, dat het niet net andersom is:
Pedofilie is gelukkig zeldzaam. Precieze getallen zijn er niet, schattingen lopen uiteen van 0,1 procent tot 4 procent. Laten we uitgaan van 1 procent. Als je dan 1.000 mannen scant zijn er 10 pedofiel. Stel nu eens dat de specificiteit 88 procent was, en de sensitiviteit 100 procent (dus dat er nooit een pedofiel wordt gemist). Dan zou je alle 10 pedofielen eruit vissen, maar tegelijk ook 120 mannen ten onrechte beschuldigen (12 procent van die 1.000). Met de door Ponseti behaalde specificiteit van 100 procent beschuldig je nooit een man ten onrechte, maar haal je wel 9 van de 10 pedofielen eruit. Tot zover de wiskunde.

Tsja, tot zover gaat misschien de wiskunde van Victor Lamme. En dat is wel een beetje gênant, want het geeft een volstrekt verkeerd beeld. De specificiteit van de test van Ponseti is de uitkomst van een steekproef en is hooguit de beste schatting van de ‘echte’ specificiteit. Je kunt niet uit het feit dat geen van de 32 gezonde proefpersonen als pedofiel word aangewezen, afleiden dat de specificiteit precies 100 procent is.
Het is eenvoudig in te zien dat je net zo goed kunt stellen dat die specificiteit bijvoorbeeld maar 95 procent is (één op twintig is dan fout-positief). Ook dan is de kans behoorlijk groot dat je de 32 mannen in het goede vakje plaatst. Die kans is gelijk aan het niet gooien van ’20’ in 32 beurten met een dobbelsteen met 20 vlakken: ongeveer 19 procent (0,95 tot de macht 32). Een kleine kanttekening moet ik hierbij wel maken, je gaat er dan van uit dat er wel een zekere spreiding in de gemeten waarden is. Maar dat blijkt wel uit het vervolg.
Wil je preciezer berekenen wat die specificiteit voor waarden kan hebben, kun je een van de vele tools op Internet gebruiken. Als je de steekproefresultaten invoert, kom je uit op een 95 procent betrouwbaarheidsinterval van 87 tot 100 procent. Dat is even wat anders dan te stellen dat Ponseti’s test geen fout-positieven kan opleveren! Er is zelfs nog een kans van één op twintig dat de specificiteit in werkelijkheid lager is dan 87 procent. [update: deze tools blijken niet zo precies in dit geval. De echte ondergrens is 91 procent. Zie de commentaren.]
Het rekenwerk van Ponseti
De valse zekerheid van het abstracte gegoochel met getallen wordt ook wat duidelijker als je bekijkt hoe die test van Ponsetti nou eigenlijk in elkaar steekt. Het artikel Assessment of Pedophilia Using Hemodynamic Brain Response to Sexual Stimuli is niet voor iedereen toegankelijk, maar ik kan er wel het een en ander over vertellen. In het onderzoek werden aan proefpersonen vier soorten blote plaatjes getoond van vrouwen, meisjes, mannen en jongens. Bij elke vertoning van een afbeelding werden fMRI-scans gemaakt. Dat levert plaatjes als hierboven op. Deze plaatjes, in feite een hele berg getallen, worden omgezet in een waarde die aan moet geven hoe opgewonden de proefpersoon is. Dit kan al op heel veel verschillende manieren, die je met een ander soort meting (die ook onnauwkeurigheden heeft) moet toetsen. Vervolgens worden er per proefpersoon twee uitkomstwaarden berekend, namelijk het verschil in opwinding bij het zien van vrouwen ten opzichte van meisjes en het verschil tussen het zien van mannen en jongens. Met die waarden kun je alle proefpersonen in een grafiekje zetten.
De test die Ponseti nu eigenlijk heeft bedacht, bestaat voor het belangrijkste deel in het bepalen van een verdeling van het vlak van de grafiek in twee delen. De verdeling moet zodanig zijn dat in het ‘goede’ stuk alle ‘normale’ personen vallen en in het ‘foute’ gebied zoveel mogelijk pedofielen.
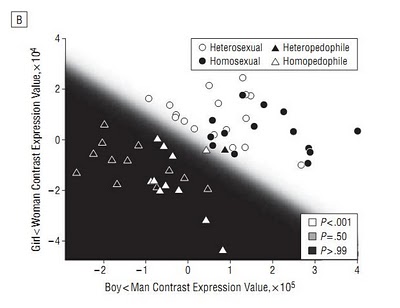
In het plaatje hiernaast is dat duidelijk gemaakt. De rondjes zijn de ‘normale’ mannen die meededen. Zij vallen allemaal in het goede, witte, gebied. Er zijn een paar pedofielen, de driehoekjes, die er echter ook in vallen. Dat zijn de fout-negatieven.
Je kunt (en moet) je afvragen of deze verdeling niet heel erg afgestemd is op deze 56 deelnemers aan het onderzoek, of andere verdelingen niet net zo goed zouden zijn. Dat doen de onderzoekers gelukkig ook wel een beetje en ze deden een zogenaamde ‘leave-one-out crossvalidation‘. Je laat dan telkens één persoon uit de dataset, doet opnieuw de verschillende splitsingen in zwart en wit in de grafiek en kijkt of de weggelaten persoon in het goede vlak zou vallen. De beste methode bleek deze simpele lineaire verdeling te zijn.
Het is dus ook helemaal niet zo dat er van tevoren een test bedacht is, die in het onderzoek zo bleek uit te pakken dat die een specificiteit van 100 procent geeft. Nee, de test is achteraf zo afgesteld dat die in ieder geval die specificiteit geeft. Het bijzondere is alleen dat je dan nog zo’n hoge sensitiviteit overhoudt.
Mooie oplossing, of niet?
Allemaal leuk en aardig, maar waar zijn we nu eigenlijk helemaal mee bezig? Is het resultaat wel generaliseerbaar naar de gehele populatie? Die 24 pedofielen zijn misschien wel helemaal niet representatief voor alle pedofielen, die we zouden willen testen. Deze waren namelijk allemaal al ‘uit de kast gekomen’ en zaten in programma’s om om te leren gaan met hun pedofilie.
Dat is één probleem, maar er zijn ook fundamentele twijfels aan de waarde van dit rekenwerk op basis van fMRI-scans. Bert Keizer stelt in een stuk in Trouw zeer terecht de vraag of we wel kúnnen weten wat we meten met zo’n hersenscan en wat voor conclusies we mogen trekken op basis daarvan:
Stel dat een pedofiel van wie we het niet vermoeden, maar die voor deze test gescreend wordt, bij het zien van pedoplaatjes helemaal geen plezier beleeft, maar zich schaamt? Precies dezelfde schaamte die, plaatsvervangend, wordt gevoeld door de hetero die ernaar kijkt. Wat zeggen we als Robert M. brandschoon blijkt op zo’n scan? Dat hij eigenlijk niks gedaan heeft? De drogreden blijft dat je op basis van een scan precies weet wat er door iemand heen gaat én dat je op grond daarvan gedrag kunt voorspellen.
Victor Lamme geeft in zijn column niet alleen een verkeerde weergave van de betrouwbaarheid van de ‘pedoscan’ maar verwacht er ook veel te veel van:
Was het Amsterdamse drama dat Robert M. heeft aangericht hiermee voorkomen? Het lijkt me dat een pedofiel niet eens gaat solliciteren als hij weet dat er van zijn brein een dergelijke scan wordt gemaakt. Een crèche kan zich mooi onderscheiden in de nu zo moeilijke markt voor kinderopvang: ‘onze medewerkers zijn pedoscanproof!’
Het kan best zo zijn dat pedofielen minder zullen solliciteren naar functies in de kinderopvang als dit soort detectie ingang vindt. Maar dat maakt de kans alleen maar groter dat iemand die wel solliciteert en positief uit de test komt, geen pedofiel is. En de term ‘pedoscanproof’ wekt, bij mij in ieder geval, eerder de suggestie dat er geen fout-negatieven zouden voorkomen. En die zijn er dus juist wel met de test van Ponseti. Ook is er onderzoek dat aantoont dat soortgelijke tests die gebruikt worden voor leugendetectie, te foppen zijn.
De valse zekerheid van dit soort testen zal hopelijk niet zo gaan uitpakken, dat we begeleiders in de kinderopvang die ‘slagen’ voor de test blindelings gaan vertrouwen. En dat we zeer verstandige maatregelen, zoals minstens twee begeleiders tegelijkertijd op een groep, overboord gaan gooien, omdat je dan kunt bezuinigen in deze ‘nu zo moeilijke markt voor kinderopvang‘.
Een paar andere artikelen over het onderzoek van Ponseti:
- Discover Magazine: Can Brain Scans Detect Pedophiles?
- Neuroskeptic: To Catch A Predator… With A Brain Scanner?
Steun Kloptdatwel
 Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
NB de rekening staat op naam van Maarten Koller, formeel eigenaar van deze site.
Ik vind de kritiek in zijn geheel eigenlijk nogal zwak. Het komt in mijn optiek op het volgende neer:
– De specificiteit hoeft geen 100% te zijn, maar kan ook een andere zeer hoge waarde hebben.
– De resultaten zijn niet per se generaliseerbaar (Victor Lamme zegt “met de door Ponseti behaalde specificiteit van 100 procent” en niet “de pedoscan HEEFT een specificiteit van 100 procent”).
– De verdeling is posthoc gedaan (“Het bijzondere is alleen dat je dan nog zo’n hoge sensitiviteit overhoudt”).
Ik denk juist dat het onderzoek redelijk duidelijke data heeft opgeleverd. Dat de verdeling posthoc is gedaan, kun je oplossen door het opnieuw te testen, eventueel met een veel grotere populatie. Laat nog wat onderzoekers ermee aan de gang gaan, kijk of ook zij allemaal verschillen vinden en zo ja, dan kun je daar weer verder onderzoek naar doen (wie wat waar waarom hoe). Ik wil niet zeggen dat er geen kritieken zijn op het onderzoek, maar het is het niet waard om een heel artikel op te offeren aan het onderzoek zelf.
So far so good, zou je zeggen. Dat is het echter niet. Stel dat er een wezenlijk verschil is tussen de gemiddelde fMRI-resultaten van de pedofiele groep en de ‘normale’ groep. Dat kan. Het probleem is dat je daar niks aan hebt. Een fMRI-scan is namelijk alleen goed met groepen proefpersonen, niet met individuele proefpersonen. Oftewel; je kunt nooit 1 persoon in de scanner leggen en kijken of hij/zij pedofiel is.
Waarom niet? Dat heeft bijvoorbeeld te maken met de manier van dataverwerking. Geen enkele brein is exact hetzelfde. Als je twee hersenen naast elkaar legt, dan kom je al snel tot de conclusie dat er bijna geen ordening zit in de kronkels aan de buitenkant van de hersenen. Daarnaast kunnen de vorm, de grootte, de dikte van de kronkels, etc., allemaal van elkaar verschillen. Toch zien alle fMRI-afbeeldingen er hetzelfde uit. Dit komt doordat ze de hersenen ‘morphen’. De afbeeldingen van de hersenen worden vervormd totdat ze in het ‘standaardmodel’ van de hersenen passen. Hierdoor verlies je niet alleen veel data over het individu, maar daarnaast kun je niet garanderen dat de hersendelen van de proefpersoon overeenkomen met die van het standaardmodel. Daarom werkt een fMRI het beste met gemiddelden; gemiddeld gezien klopt het morphen op zich wel, maar voor een individu gewoon niet.
Er kleven nog veel meer nadelen aan een fMRI (al helemaal voor individueel gebruik), dus een ‘pedoscan’ zie ik er niet aan komen.
Dat de specificiteit niet 100 procent is, maar een andere heel hoge waarde kan hebben, is wel essentieel in mijn kritiek op Lamme’s stuk. Lamme bouwt zijn verhaal wel degelijk op rond het idee dat zo’n pedoscan zo kan werken dat je nooit mensen ten onrechte beschuldigd. Hij zegt inderdaad ‘met de door Ponseti behaalde specificiteit’ maar als hij een theoretische 100 procent van een verder te ontwikkelen pedoscan had bedoeld, had hij het hele onderzoek niet hoeven aanhalen. Ik kan het stuk niet anders interpreteren dan dat Lamme bedoelt dat een willekeurig persoon die blootgesteld wordt aan de test van Ponseti niet vals positief als pedofiel kan worden aangewezen.
De precieze bewerkingen van de fMRI-scans ken ik niet, maar die zijn mijns inziens niet zo belangrijk voor het verhaal. Het morphen is gewoon een extra bewerking. Je hebt als input een hele bak getallen en daar komen er in de test van Ponseti via ingewikkelde rekenpartijen in eerste instantie twee waarden per persoon uit en die worden weer in zwart/wit verdeeld. Vóór die laatste stap is er nog steeds sprake van een redelijke spreiding van de gegevens en zul je altijd ook te maken krijgen met vals positieven als je de test op een grotere groep uitvoert.
Wat bedoel je trouwens met je zin: “Ik wil niet zeggen dat er geen kritieken zijn op het onderzoek, maar het is het niet waard om een heel artikel op te offeren aan het onderzoek zelf.”?
Ik heb de getallen nagerekend en er een foutje uitgehaald, maar ik snap nog steeds niet hoe het 95% betrouwbaarheidsinterval bij een resultaat van 32 uit 32 kan lopen van 87% tot 100%. Het betekent kennelijk dat je bij 13% fout-positieven nog een kans van vijf procent hebt dat je 32 uit 32 goedkeurt.
Maar 0,87 tot de macht 32 is 0,011. Pas 0,91 tot de macht 32 is gelijk aan 0,05.
Nou ja, 87% en 91 % maakt niet zoveel uit. Wat erger is, is wat Pepijn ook zegt: die zogenaamde 100% is het product van geknutsel aan de data nadat ze verkregen zijn, in het bijzonder het trekken van de grens tussen zwart en wit. Al die statistische rekenwijzen zijn bedoeld voor ‘tests’ die al voor de proef vastlagen.
Laat ik een analogon geven. Ik bedenk een test voor valsemunters. Ik laat een stel valsemunters en een controlegroep gewoon zesmaal een dobbelsteen gooien. Ik schrijf alle resultaten op, en ga aan het puzzelen. Valsemunters zullen, zo vermoed ik, sterke afwijkingen van de verwachte aantallen geven. Als mogelijkheden heb ik: teveel zessen, teveel vijven enz. of te hoge som of te lage som of juist een opvallend gelijkmatige verdeling, en misschien nog wel andere ‘opvallende’ resultaten, zoals een monotoon niet-dalende rij enz. Na afloop van de gegevensverzameling ga ik pas bedenken welke afwijking kenmerkend is voor de valsemunters. Dan is het niet zo verbazingwekkend als mijn nieuw bedachte test dan behoorlijk lage specificiteit heeft.
(Ik kan nooit onthouden of specificiteit nou het complement van fout-positief of fout-negatief is, maar ik heb een ezelsbruggetje bedacht: fout-positief hoort bij specifiek, want die hebben allebei een p, en fout-negatief hoert bij sensitief, want die hebben allebei een n. Zo, nou kan ik dat niet meer vergeten, maar ik blijf fout-positief duidelijker vinden.)
Dit voorbeeld is misschien wat gechargeerd, maar ik ben ervan overtuigd dat dit soort achterafgeknutsel schering en inslag – of moet ik zeggen kanker – is in geneeskundig onderzoek, en ik kan daar nog wel meer over zeggen, maar vanwege ‘Erp’s Law’ zal ik het niet doen. In elk geval heeft Ioannidis daar ook over geklaagd, alleen heeft die volgens mij zijn verhaal weer veel te gecompliceerd gemaakt. Maar als je een mooi voorbeeld wilt hebben van achteraf met random gegevens gaan knutselen, moet je op de Skepsis siute even zoeken naar ‘Druten’. Daar kun je vinden hoe Dick Bierman het klaarspeelde om delen van de output van een radmomngenerator achteraf naar ‘heel bijzonder’ te knutselen. En hij had niet eens een groep valsmunters, maar gewoon één stout jongetje.
Het resultaat van Lamme is op zijn best een exploratief resultaat. Je zou de complete test nu moeten gebruiken voor twee nieuwe populaties: personen die ‘normaal’ zijn, en pedofielen. En dan niet achteraf weer een nieuwe rekenwijze invoeren: per persoon binnen 1 seconde nadat de scan is gemaakt (zoveel rekenwerk is het toch niet?) automatisch een pedofilie-index afleveren, en dan eens kijken of je bij 500 normale personen inderdaad nul maal de grenswaarde voor pedofilie overschrijdt.
Je kunt de redenering van Lamme omdraaien. Stel, je wilt een test die maar 1 op 10 keer ten onrechte iemand als pedofiel aanwijst (nog te veel volgens mij vanwege het enorme stigma dat aan pedofilie kleeft, maar goed). Laten we aannemen dat dat alleen kan door flink wat pedofielen door te laten, bijvoorbeeld de helft (ook teveel, maar zonder dat gegeevns is het lastig rekenen). Dus als je 10.000 mensen test zitten daar 100 pedo’s bij, en je vindt er 50. Van de overige 9900 mag je dan maar 5 positieven, dus fout-positieven, vinden. De specificiteit moet dus 9895/9900 zijn. Bij welke steekproefomvang kun je dan ‘veilig’ concluderen dat de specificiteit wel goed zit als je 100% correct scoort in de steekproef (een echte steekproef, dus niet achteraf knutselen)? Ik kom op ongeveer 6000.
Met andere woorden, als Lamme nou eens eerst een test had bedacht, en die zonder achterafgeknutsel had toegepast op 6000 gegarandeerd normale proefpersonen en dan ook nog alle 6000 normaal bevonden met de test, dan had hij enig recht van spreken gehad. (Hoe garandeer je van 6000 personen trouwens dat ze absoluut geen neiging tot pedofilie hebben?)
Er is nog iets: hoe kwam Ponseti aan zijn pedo’s? Als hij veroordeelde pedo’s nam, dan is het best mogelijk dat plaatjes van blote kindertjes emoties opwekten omdat die verband hielden met de veroordeling, betrapt zijn, sociale uitsluiting ondervinden en dergelijke. Je weet niet eens of de test wel werkt voor niet-veroordeelde pedo’s. Misschien heeft hij daar wat op bedacht. Maar dat is wel heel erg essentieel.
Dank voor de correcte Jan Willem! Ik had de waardes (81% en 19%) even verwisseld. Ik zal nog eens even proberen uit te vogelen hoe dat precies zit met dat betrouwbaarheidsinterval, ik had verschillende ‘calculators’ geprobeerd die wel allemaal dezelfde uitkomst gaven. Dat dat interval nogal ‘breed’ uitpakte, was juist de reden dat ik het voorbeeld met 95 procent gaf ter illustratie.
Het gebruik van fout-negatief en fout-positief is inderdaad een stuk duidelijker dan de s-woorden.
Die pedofielen van Poseti werden geworven onder de personen die zichzelf hadden aangemeld bij hulpprogramma’s (anoniem). Of er ook tussen zaten met een eerdere veroordeling, staat geloof ik niet in het artikel.
Nog even in het artikel opgezocht: 12 van de pedofielen die meededen, hadden eerder seksuele vergrijpen gepleegd!
Ik vraag me af wie er dan nog meer aan die hulpprogramma’s meededen. Ik denk dat er toch wel enige druk is uitgeoefend op de deelnemers. Het zouden ook geestelijken kunnen zijn waarover klachten geweest.
De berekening van dat betrouwbaarheidsinterval gebeurt in die ‘calculators’ blijkbaar altijd met een benaderingsformule. Bij waarden dicht bij 1 (of 0) en niet zo grote aantallen, geeft dat teveel vertekening en moet je het exact doen. Dan is 91% de correcte ondergrens.
Ik vindt het eigenlijk raar dat men het woord “beschuldigen” hier gebruikt. Men kan toch niemand beschudigen om hoe zijn/haar hersens eruit zien voordat deze persoon ook maar een vergrijp heeft gepleegd? Overigens is dit ook niet juist te stellen dat men sec naar de hersenen kijkt, een suggestie die wel wordt gewekt, maar men kijkt naar een response bij het kijken van beelden. Dus in weze is de methode niet zo revolutionair omdat deze niet zo verschillend is als eerdere methodes waarbij men verschijnselen van opwinding probeert te detecteren. Ik vind het nogal wat dat hij het woord beschuldigen gebruikt terwijl de proefpersonen, neem ik aan, vrijwillig hebben meegewerkt, misschien wel met het idee dat dit onderzoek tot verbeterde therapieen zou kunnen leiden. Misschien wel mensen die leiden onder hun verlangens, maar hier geheel terecht niet aan toegeven, in tegenstelling tot Robert M. Bovendien, vanuit het oogpunt van de creche is het toch juist beter om soms onterecht iemand te weigeren die eigenlijk toch gezond is dan dat er af en toe toch een pedo door de mazen van het net glipt? Afgezien van het feit of zo’n test uberhaupt een goed idee is om toe te voegen bij een sollicitatie procedure.
Het 2de woord “leiden” moest “lijden” zijn in bovenstaande natuurlijk. En gezien de proefpersonen zich blijkbaar vrijwillig hadden aangemeld bij hulpprogramma’s, zoals blijkt uit Pepijn’s commentaar, kan ik me indenken dat ze zich gekwetst zullen voelen met hoe de onderzoeker hun groep aanspreekt. De onderzoeker heeft hiermee misschien wel een averechts effect veroorzaakt omdat deze groep nu nog minder vaak naar een hulpverlener zal toe stappen. Dit vindt ik eigenlijk nog kwalijker dan zijn gegoochel met getallen.
Geen idee wat de plaatjes Boys vs Men en Girls vs Women voorstellen, want ik kan de ondertiteling niet lezen. Wat ik echter wel kan lezen is : pedophiles and healthy volunteers. De auteurs beschouwen pedofilie dus als een ziekte. Daar kan Robert M. zijn voordeel mee doen.
In het abstract zeggen Ponseti c.s. dat hun onderzoek bedoeld is voor de verbetering van de behandeling van pedofielen, vanwege de beperkte betrouwbaarheid van fallometrie. Probleem is dat iedereen, gezien de huidige gepreoccupeerdheid van de samenleving met pedofilie, daarin prompt een opsporingsmiddel ziet. NeurowetenschapperVictor Lamme had tenminste enige woorden aan het doel van het onderzoek kunnen wijden, alvorens op te roepen tot het scannen van de halve bevolking.
Ik heb nog een ander probleem met dit soort onderzoeken, en dat is dat ze altijd uitgaan van het model “visuele prikkel (en dan ook nog uitsluitend foto’s) levert al of niet een reactie”. Dat lijkt mij een uiterst simplistisch model voor zoiets gecompliceerds als de menselijke seksualiteit. Is er nooit enige hersenreactie van seksuele aard te zien bij helemaal geen externe prikkel, of bij bij voorbeeld auditieve prikkels ? Opvallend is ook dat er in het hele maatschappelijke debat vanuit wordt gegaan dat vrouwen per definitie geen pedofiele neigingen hebben. Ponseti c.s. zullen te weinig veroordeelde vrouwelijke pedofielen ter beschikking hebben gehad, maar dat wil niet zeggen dat ze er niet zijn.
Ik denk dat per persoon het verschil in hersenactiviteit is onderzocht bij het zien van een blotejongetjesplaat en een blotemannenplaat. Elke proefpersoon levert dan een verschilplaatje. die verschilplaatjes worden dan gemiddeld over de hele pedo-groep en ook over de hele normale groep. Dan maak je weer een verschil tussen die twee gemiddelden.
Een MRI-plaatje is eigenlijk een serie dwarsdoorsneden door het brein, in dit geval min of meer horizontale, en dan telkens een vaste afstand (een of twee millimeter) hoger. Daarom gaat in het plaatje linksboven de doorsnede door de ogen. Die zie je ook zitten. Het plaatje daarnaast is al iets hoger, daar zie je (nog) minder van de ogen. Bij het laatste plaatje zie je dat de dwarsdoorsnede hoog in de schedel is, daar is de omtrek al kleiner.
Aan de rechterkant nog zo’n ‘verschil van gemiddelde verschillen’-prent, maar dan van blotekleinemeisjesplaat vs. blotevrouwenplaat.
De suggestie is dus dat pedofielen (althans degenen die aan het onderzoek meededen) voornamelijk vielen op kleine jongetjes, maar het kan ook betekenen dat ze op vrouwen en kinderen gelijkelijk vielen (in het bijzonder dat volwassen vrouwen en kleine meisjes niet zoveel uitmaakten), maar alleen niet op volwassen mannen.
Zo’n MRI maakt een enorm lawaai. Dat komt omdat er van heel veel kanten ‘gemeten’ wordt, en het meetapparaat moet dus telkens een stapje roteren, stoppen, radiozender en detectors overal in het rond aan en weer uit, en dat herhalen. Dat veroorzaakt het geratel. Dus auditieve stimuli zijn volgens mij niet zo makkelijk te realiseren in zo’n machien.
Vandaag nog een interessant artikel van Bert Keizer:
http://www.trouw.nl/tr/nl/5116/Filosofie/article/detail/3234306/2012/04/01/We-zijn-meer-dan-ons-brein.dhtml
Hersenonderzoekers die de mens reduceren tot neuronen in ons hoofd, hebben het mis. De mens bestaat, met zijn vrije wil, zijn emoties, met al zijn grilligheden.
Noot:
Op vrijdag 13 april gaat Bert Keizer tijdens de Nacht van de Filosofie (Felix Meritis, Amsterdam) in debat met Dick Swaab (‘Wij zijn ons brein’).
Het lijkt me dat beide partijen de zaak erg versimpelen. Ons taalgebruik is gekoppeld aan wat we bewust over ons zelf ervaren. Dat taalgebruik is hopeloos inadequaat om het functioneren van 100.000.000.000 hersencellen (elk met 1000 of 10.000 verbindingen met andere cellen) te beschrijven. Het zit er dik in dat een groot aantal van die verbindingen samen ons geheugen vormen. Het brein is dus een processor van pak hem beet een biljoen gigabyte. Het zit er dus trouwens ook dik in dat wat je met een hersenscan of ander beeldvormende apparatuur aan de hersenen kunt zien een biljoen maal zo weinig is als wat er ‘is’.
Neem nou het volgende stukje uit het artikel:
“Besluit” is een woord uit onze taal. Libet ontdekte dat de neuronale activiteit die leidt tot 2, een fractie van een seconde eerder begint dan het ogenblik waarop men zich bewust wordt van dat “besluit”.
Gisteravond vroeg mijn echtgenote me naar de naam van een voormalige collega van haar. Ik kon er niet op komen. Vanochtend, nog half in slaap, dacht ik terug aan die vraag en wist het antwoord meteen. Dat is een heel gewone ervaring.
Tal van handelingen, onder andere de besturing van mijn vingers terwijl dit tik, gebeuren zonder dat ik voor elke spier die ik beweeg een bewuste beslissing neem.
Als je om je heen kijkt, zorgt het visuele deel van je hersenen ervoor dat er automatisch perspectiefcorrecties (en andere correcties) worden toegepast. Dus wanneer je over een straat met vierkante stoeptegels loopt en om je heen kijkt, verspringt uiteraard het beeld op je netvlies voortdurend. Niettemin ‘zie’ je de tegels allemaal hun vierkante vorm behouden en keurig niets onbeweeglijk op hun plaats blijven liggen terwijl je er langs loopt en af en toe ook nog naar andere dingen kijkt. Trouwens als je leest, en je ogen ‘langs de regel’ gaan zie je de woorden niet van positie veranderen, hoewel de PLEK waar dit dikgedrukte woord op je netvlies valt voortdurend verandert.
Ik kan nog wel even doorgaan met alles wat automatisch en zelfs zonder dat we het merken tussen onze oren gebeurt. Dat het buiten of onder ons bewustzijn gebeurt wil niet zeggen dat iemand anders het doet, toch?
Zonet noemde ik het opeens weer herinneren, maar in feite weten we natuurlijk helemaal niet wat er gebeurt als we ons iets herinneren, omgeacht of we dat meteen doen of met enige vertraging.
Het komt me voor dat de protesten tegen de opvattingen van Swaab net zo misplaatst zijn als bezwaren tegen de opvatting dat ook mooie schilderijen uit atomen bestaan. De mensen die daar tegen argumenteren (en trouwens mensen die daar juist voor argumenteren) doen hoofdzakelijk wat we allemaal doen: bij een al bestaande opvatting argumenten pro zoeken. Maar alle argumenten in dezen stellen de zaak te simpel voor. Het menselijk brein is echt heel gecompliceerd. En wat gecompliceerd is, produceert vaak op volkomen determistische manier volstrekt onvoorspelbare resultaten. In de buitengewoon overzichtelijke mechanica begint ‘gecompliceerd’ al bij ‘meer dan dan twee componenten’, en dan kunnen we voorlopig een processor van een biljoen gigabyte waarvan we het bouwplan niet kennen wel vergeten.
Als we het menselijk brein volledig zouden kunnen “begrijpen”, zou ons brein zo simpel zijn, dat we het onmogelijk zouden kunnen begrijpen.
Ik denk dat de bezwaren tegen de opvattingen van de heer Swaab ook voortkomen uit het feit dat deze opvattingen door bepaalde mensen misbruikt worden door min of meer te stellen dat ze helemaal geen invloed hebben op hun eigen gedrag, of dat andere mensen geen invloed hebben op hun eigen gedrag en dat er dus helemaal geen vrije wil bestaat. De consequenties hiervan zijn in feite dat bijvoorbeeld een misdrijf voortvloeit uit iemands brein en dat de misdadiger daar helemaal geen invloed op heeft. Als mensen niet verantwoordelijk zijn voor hun eigen gedrag, hoe kunnen we ze daarvoor dan straffen.
Je kunt straffen zien als een vorm van conditionering. Je kunt allerlei dieren van alles en nog wat bijbrengen door ze te ‘belonen’ als ze het goed doen, en ze te ‘straffen’ als ze het verkeerd doen. Dat werkt natuurlijk bij mensen ook.
Het maakt nauwelijks wat uit of iemand gestraft wordt voor een weloverwogen beslissing of voor iets waar hij of zij misschien meer op het gevoel gehandeld heeft.
Voorts brengt onze aanleg als sociaal wezen met zich mee dat we een waarschijnlijk ingebakken neiging hebben om personen die zich asociaal gedragen te ‘straffen’. Dat leidt echter makkelijk tot eigenrichting en straffen zijn dan behalve een middel om gedrag (van daders) te beïnvloeden ook een middel om eigenrichting (door slachtoffers en omstanders) te voorkomen.
In het huidige strafrecht maakt het een groot verschil of iemand iets ‘per ongeluk’ gedaan heeft, of onverantwoordelijk nalatig is geweest of iets opzettelijk gedaan heeft of zelf ‘met voorbedachten rade’, namelijk wetende dat het niet mag en maatregelen nemen om te voorkomen dat de dader ontdekt of gepakt wordt.
Dat past eigenlijk ook wel in wat ik maar even de Swaab-opvatting noem. We doen allemaal dingen waar we niet zo over nadenken. (Allerlei prestaties in de topsport berusten op zware training waardoor men ‘automatisch’ meteen doet wat veel te veel tijd zou kosten als we moesten wachten op een bewust genomen beslissing.) Maar bij gecompliceerdere handelingen is er vaak voldoende tijd om na te denken en dingen wel of niet te doen, afhankelijk van de uitkomst van de gedachte. Het lijkt daarom redelijk om zwaarder te straffen naarmate de dader meer tijd heeft gehad of genomen om na te denken.
De vraag is in feite of de ideeën van de heer Swaab het bestaan van een vrije wil en dus van eigen verantwoordelijkheid geheel uitsluiten. Als je er van uit gaat dat een dader de tijd heeft gehad om over z’n gedrag na te denken, dan zou je dus kunnen zeggen dat er in zekere mate een vorm van vrije wil bestaat, ook al is die vrije wil dan niet absoluut. Iemand als Marcel van Dam gebruikt de ideeën van de heer Swaab om te stellen dat mensen helemaal niets aan hun eigen gedrag kunnen veranderen. Het vreemde is natuurlijk dat in het verleden de heer Buikhuizen door een linkse columnist is afgebrand om z’n opvattingen dat crimineel gedrag in de hersenen zit en dat momenteel een linkse columnist in de ideeën van de heer Swaab hetzelfde lijkt te lezen en het derhalve min of meer verontschuldigd.
Kortweg:
Piet Grijs over Buikhuizen: “Hij wil jullie hersenen onderzoeken, om te zien of jullie later crimineel worden en dat is een schande, want dan zou men jullie preventief op kunnen sluiten.”
Marcel van Dam met het boek van Swaab in de hand: “De crimineel is nu eenmaal crimineel, omdat dit in z’n hersenen zit en kan dus niet verantwoordelijk worden gehouden voor z’n eigen gedrag.”
Op het Skepp-forum heeft een hele discussie plaatsgevonden over het bestaan van de vrije wil, waarbij sommigen dus bijna fatalistisch stelden dat er helemaal geen vrije wil bestond. De vraag daarbij blijft in feite wat je als vrije wil wilt beschouwen.
Misschien drijft de discussie wat af van het oorspronkelijke onderwerp. Maar ik heb ook vaker met dit soort van discussies van doen gehad. Maar ik ben het met Renate eens dat je eigenlijk niet om vrije wil heen kan, voor een nuttige beschrijving van de samenleving, die tesamen met onze impulsen, driften, instinkten, genen onze handelingen bepalen. Misschien is het waar dat we te veel handelingen achteraf toeschrijven aan een wel overwogen beslissing terwijl dat niet zo is. Maar ik snap niet zo goed die mensen die een volledig absoluut deterministische wereld blijven verdedigen (maar in hun eigen visie kunnen ze daar natuurlijk niks aan doen). Zo’n deterministische theorie is nooit te weerleggen net zoals veel andere matrix-achtige theorieen dat alles in feite illusie is, maar filosofisch gezien is deterministisch niet erg nuttig. Anders zou je net zo goed van 10 hoog uit een flatgebouw kunnen springen, als het lukt, had je achterafgezien niks anders dan dat kunnen doen. Maar als je toch een vrij wil had, dan krijg je misschien wel spijt tijdens je val. Dus het is verstandiger om in ieder geval te denken dat je een vrije wil hebt en je hiernaar te gedragen. Dus neem je beslissingen weloverwogen (spring niet uit het raam), dit geeft het beste resultaat indien vrije wil bestaat en je had zowiezo niet anders kunnen doen mochten alles uiteindelijk toch deterministisch zijn.