Sinds enige tijd schrijft Victor Lamme, hoogleraar Cognitieve Neurowetenschap aan de Universiteit van Amsterdam, columns in de krant nrc.next. Op 16 maart publiceerde hij er een met de titel ‘De pedoscan‘. Die is gewijd aan het onderzoek van Jorge Ponseti waarin die bekijkt of je met hersenscans onderscheid kunt maken tussen pedofielen en ‘normale’ mensen. Opmerkelijke conclusie van dat onderzoek is dat dat vrij precies mogelijk lijkt te zijn. Ponseti ontwikkelde een test waarin proefpersonen werden blootgesteld aan plaatjes van naakte volwassenen en kinderen. En door te kijken hoe verschillend de scans eruit zien, kan met een hoop rekenwerk ‘bepaald’ worden of iemand pedofiel dan wel ‘normaal’ is. Maar dit soort rekenpartijen op basis van meetgegevens hebben toch altijd te maken met marges, fout-positieven en dat soort statistische kanttekeningen? Hoe zit het daar mee? Victor Lamme trekt in ieder geval niet de goede conclusies uit het gecijfer. Een 100 procent betrouwbare pedoscan ligt nog niet om de hoek.

Bij zo’n beetje elke test die twee uitslagen geeft, positief of negatief, heb je naast de correcte (positieve en negatieve) uitslagen ook fout-negatieve en fout-positieve uitslagen. Een fout-negatieve uitslag wil zeggen dat je test de eigenschap niet aanwijst, terwijl die er in werkelijkheid wel is. Een fout-positieve uitslag is net andersom: de eigenschap wordt ten onrechte aangetoond door de test.
Nu wil je graag dat een test zo weinig mogelijk fout-negatieve resultaten geeft, dat heb je een hoge sensitiviteit, maar ook zo weinig mogelijk fout-positieve, een hoge specificiteit. Meestal is het lastig om zowel de sensitiviteit als de specificiteit heel hoog te krijgen. Vooral in juridische aangelegenheden is een hoge specificiteit van belang, je wil immers niet mensen ten onrechte beschuldigen.
Hoe betrouwbaar is de ‘pedoscan’?
De resultaten van Ponseti zijn zo mooi, omdat zijn test de hersenscans van de 32 ‘normale’ proefpersonen allemaal als ‘normaal’ herkende, een specificiteit van 100 procent! Op de sensitiveit moet dan wel wat ingeleverd worden, want van de 24 pedofielen, werden er 3 niet juist geïdentificeerd. De sensitiviteit is dus 21/24 = 88 procent, afgerond. Lamme legt uit waarom het zo belangrijk is, dat het niet net andersom is:
Pedofilie is gelukkig zeldzaam. Precieze getallen zijn er niet, schattingen lopen uiteen van 0,1 procent tot 4 procent. Laten we uitgaan van 1 procent. Als je dan 1.000 mannen scant zijn er 10 pedofiel. Stel nu eens dat de specificiteit 88 procent was, en de sensitiviteit 100 procent (dus dat er nooit een pedofiel wordt gemist). Dan zou je alle 10 pedofielen eruit vissen, maar tegelijk ook 120 mannen ten onrechte beschuldigen (12 procent van die 1.000). Met de door Ponseti behaalde specificiteit van 100 procent beschuldig je nooit een man ten onrechte, maar haal je wel 9 van de 10 pedofielen eruit. Tot zover de wiskunde.

Tsja, tot zover gaat misschien de wiskunde van Victor Lamme. En dat is wel een beetje gênant, want het geeft een volstrekt verkeerd beeld. De specificiteit van de test van Ponseti is de uitkomst van een steekproef en is hooguit de beste schatting van de ‘echte’ specificiteit. Je kunt niet uit het feit dat geen van de 32 gezonde proefpersonen als pedofiel word aangewezen, afleiden dat de specificiteit precies 100 procent is.
Het is eenvoudig in te zien dat je net zo goed kunt stellen dat die specificiteit bijvoorbeeld maar 95 procent is (één op twintig is dan fout-positief). Ook dan is de kans behoorlijk groot dat je de 32 mannen in het goede vakje plaatst. Die kans is gelijk aan het niet gooien van ’20’ in 32 beurten met een dobbelsteen met 20 vlakken: ongeveer 19 procent (0,95 tot de macht 32). Een kleine kanttekening moet ik hierbij wel maken, je gaat er dan van uit dat er wel een zekere spreiding in de gemeten waarden is. Maar dat blijkt wel uit het vervolg.
Wil je preciezer berekenen wat die specificiteit voor waarden kan hebben, kun je een van de vele tools op Internet gebruiken. Als je de steekproefresultaten invoert, kom je uit op een 95 procent betrouwbaarheidsinterval van 87 tot 100 procent. Dat is even wat anders dan te stellen dat Ponseti’s test geen fout-positieven kan opleveren! Er is zelfs nog een kans van één op twintig dat de specificiteit in werkelijkheid lager is dan 87 procent. [update: deze tools blijken niet zo precies in dit geval. De echte ondergrens is 91 procent. Zie de commentaren.]
Het rekenwerk van Ponseti
De valse zekerheid van het abstracte gegoochel met getallen wordt ook wat duidelijker als je bekijkt hoe die test van Ponsetti nou eigenlijk in elkaar steekt. Het artikel Assessment of Pedophilia Using Hemodynamic Brain Response to Sexual Stimuli is niet voor iedereen toegankelijk, maar ik kan er wel het een en ander over vertellen. In het onderzoek werden aan proefpersonen vier soorten blote plaatjes getoond van vrouwen, meisjes, mannen en jongens. Bij elke vertoning van een afbeelding werden fMRI-scans gemaakt. Dat levert plaatjes als hierboven op. Deze plaatjes, in feite een hele berg getallen, worden omgezet in een waarde die aan moet geven hoe opgewonden de proefpersoon is. Dit kan al op heel veel verschillende manieren, die je met een ander soort meting (die ook onnauwkeurigheden heeft) moet toetsen. Vervolgens worden er per proefpersoon twee uitkomstwaarden berekend, namelijk het verschil in opwinding bij het zien van vrouwen ten opzichte van meisjes en het verschil tussen het zien van mannen en jongens. Met die waarden kun je alle proefpersonen in een grafiekje zetten.
De test die Ponseti nu eigenlijk heeft bedacht, bestaat voor het belangrijkste deel in het bepalen van een verdeling van het vlak van de grafiek in twee delen. De verdeling moet zodanig zijn dat in het ‘goede’ stuk alle ‘normale’ personen vallen en in het ‘foute’ gebied zoveel mogelijk pedofielen.
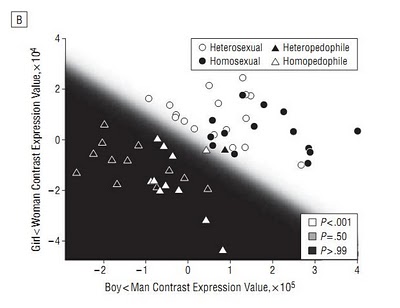
In het plaatje hiernaast is dat duidelijk gemaakt. De rondjes zijn de ‘normale’ mannen die meededen. Zij vallen allemaal in het goede, witte, gebied. Er zijn een paar pedofielen, de driehoekjes, die er echter ook in vallen. Dat zijn de fout-negatieven.
Je kunt (en moet) je afvragen of deze verdeling niet heel erg afgestemd is op deze 56 deelnemers aan het onderzoek, of andere verdelingen niet net zo goed zouden zijn. Dat doen de onderzoekers gelukkig ook wel een beetje en ze deden een zogenaamde ‘leave-one-out crossvalidation‘. Je laat dan telkens één persoon uit de dataset, doet opnieuw de verschillende splitsingen in zwart en wit in de grafiek en kijkt of de weggelaten persoon in het goede vlak zou vallen. De beste methode bleek deze simpele lineaire verdeling te zijn.
Het is dus ook helemaal niet zo dat er van tevoren een test bedacht is, die in het onderzoek zo bleek uit te pakken dat die een specificiteit van 100 procent geeft. Nee, de test is achteraf zo afgesteld dat die in ieder geval die specificiteit geeft. Het bijzondere is alleen dat je dan nog zo’n hoge sensitiviteit overhoudt.
Mooie oplossing, of niet?
Allemaal leuk en aardig, maar waar zijn we nu eigenlijk helemaal mee bezig? Is het resultaat wel generaliseerbaar naar de gehele populatie? Die 24 pedofielen zijn misschien wel helemaal niet representatief voor alle pedofielen, die we zouden willen testen. Deze waren namelijk allemaal al ‘uit de kast gekomen’ en zaten in programma’s om om te leren gaan met hun pedofilie.
Dat is één probleem, maar er zijn ook fundamentele twijfels aan de waarde van dit rekenwerk op basis van fMRI-scans. Bert Keizer stelt in een stuk in Trouw zeer terecht de vraag of we wel kúnnen weten wat we meten met zo’n hersenscan en wat voor conclusies we mogen trekken op basis daarvan:
Stel dat een pedofiel van wie we het niet vermoeden, maar die voor deze test gescreend wordt, bij het zien van pedoplaatjes helemaal geen plezier beleeft, maar zich schaamt? Precies dezelfde schaamte die, plaatsvervangend, wordt gevoeld door de hetero die ernaar kijkt. Wat zeggen we als Robert M. brandschoon blijkt op zo’n scan? Dat hij eigenlijk niks gedaan heeft? De drogreden blijft dat je op basis van een scan precies weet wat er door iemand heen gaat én dat je op grond daarvan gedrag kunt voorspellen.
Victor Lamme geeft in zijn column niet alleen een verkeerde weergave van de betrouwbaarheid van de ‘pedoscan’ maar verwacht er ook veel te veel van:
Was het Amsterdamse drama dat Robert M. heeft aangericht hiermee voorkomen? Het lijkt me dat een pedofiel niet eens gaat solliciteren als hij weet dat er van zijn brein een dergelijke scan wordt gemaakt. Een crèche kan zich mooi onderscheiden in de nu zo moeilijke markt voor kinderopvang: ‘onze medewerkers zijn pedoscanproof!’
Het kan best zo zijn dat pedofielen minder zullen solliciteren naar functies in de kinderopvang als dit soort detectie ingang vindt. Maar dat maakt de kans alleen maar groter dat iemand die wel solliciteert en positief uit de test komt, geen pedofiel is. En de term ‘pedoscanproof’ wekt, bij mij in ieder geval, eerder de suggestie dat er geen fout-negatieven zouden voorkomen. En die zijn er dus juist wel met de test van Ponseti. Ook is er onderzoek dat aantoont dat soortgelijke tests die gebruikt worden voor leugendetectie, te foppen zijn.
De valse zekerheid van dit soort testen zal hopelijk niet zo gaan uitpakken, dat we begeleiders in de kinderopvang die ‘slagen’ voor de test blindelings gaan vertrouwen. En dat we zeer verstandige maatregelen, zoals minstens twee begeleiders tegelijkertijd op een groep, overboord gaan gooien, omdat je dan kunt bezuinigen in deze ‘nu zo moeilijke markt voor kinderopvang‘.
Een paar andere artikelen over het onderzoek van Ponseti:
- Discover Magazine: Can Brain Scans Detect Pedophiles?
- Neuroskeptic: To Catch A Predator… With A Brain Scanner?