De afgelopen week kon je er haast niet om heen: de media waren in de ban van het interview van Oprah Winfrey met Lance Armstrong. Ook de NOS besteedde er ruimschoots aandacht aan: in het acht uur journaal van vrijdag 18 januari was bijna de helft van de uitzending er aan gewijd. Interessant werd het in het late journaal van die dag. Daarin werden de uitspraken van Armstrong geanalyseerd met een computerprogramma, dat uit zou kunnen maken of iemand de waarheid spreekt of liegt.
De meest opmerkelijke uitspraak die professor Eric Postma van de Universiteit van Tilburg daarin deed, was dat de analyse uitwees dat Armstrong met 80 procent kans had gelogen toen die stelde dat hij nooit betaald had om een positieve dopingtest in de doofpot te stoppen. Was deze ‘conclusie’ wel te rechtvaardigen op basis van een systeem dat nog in de ontwikkelfase zit?
Uit het korte fragment wordt niet zo snel duidelijk hoe het programma werkt. Ik mailde daarom afgelopen maandag met prof. Postma en kreeg tot mijn genoegen al heel snel een reactie met meer uitleg. Later kwam ik erachter dat hij op de radio bij omroep Brabant al ruimere gelegenheid had gekregen om uit te leggen wat de analyse inhoudt en hoe hard de uitspraken zijn.
De analyse
In het kort werkt het zo: van Armstrong werden naast het materiaal uit het interview ook oude beelden geselecteerd waarin hij uitspraken heeft gedaan, waarvan we nu weten dat ze gelogen zijn. Software die het gezicht in de videobeelden herkent en daarin een aantal punten kan volgen, levert vervolgens een heleboel data op die je kunt gaan analyseren. Is er een manier om op basis van die getallen de ware uitspraken en de leugens te scheiden? Die vraag is een mooi rekenklusje voor de computer. Als er in de data patronen zitten die zo’n scheiding mogelijk maken, zijn er meerdere manieren om die er uit te vissen. Om te checken of je niet een puur toevallige ‘fit’ hebt gevonden, doe je dan nog wat controles (bijvoorbeeld een ‘leaving-one-out cross-validatie’, een methode die ik elders ook heb beschreven).
Bij Armstrong werd een ‘idiosyncratische trek‘ gevonden die gebruikt kan worden om zijn uitspraken in ‘waar’ en ‘gelogen’ te kunnen indelen. Die ‘trek’ was in dit geval blijkbaar ook fysiek te duiden, want Postma heeft het een aantal keer over een ‘strak gelaat’, maar in zijn algemeenheid is het simpelweg een formule die gevoed wordt door de meetpunten.
Het werkt ook niet zomaar bij iedere spreker. Het kan goed zijn dat iemand te weinig variatie laat zien in zijn gezichtsuitdrukking of stemgeluid om een significante splitsing te kunnen maken tussen ‘ware’ en ‘gelogen’ uitspraken. Ook is er voldoende beeldmateriaal nodig met uitspraken waarin je zeker weet of de persoon daar zat te liegen of de waarheid sprak (op zich al een lastige beoordeling). Bij Armstrong denken de onderzoekers blijkbaar dat er aan die voorwaarden is voldaan.
Weet je wat je meet?
Is het onderscheid dat het programma maakt tussen de verschillende fragmenten inderdaad het verschil tussen waarheid spreken en liegen? Een anekdote rond neurale netwerken kan ook hier als waarschuwing dienen. Het verhaal gaat dat zo’n netwerk werd getraind om te detecteren of er gecamoufleerde tanks te zien waren in een natuurlijke omgeving. Na training met 100 foto’s deed het netwerk het fantastisch en ook nog toen het getest werd met een vergelijkbare set foto’s die vooraf apart was gelegd.
Toch klopte er iets niet; met een onafhankelijk aangeleverde set foto’s bakte het programma er niets van! Het bleek dat de trainings- en testfoto’s op een veel makkelijkere manier onder te verdelen waren in ‘tank’ of ‘geen tank’: alle foto’s met tanks waren op bewolkte dagen genomen en die zonder tanks op zonnige dagen. Het programma fungeerde dus waarschijnlijk als een belichtingsmeter. Of de anekdote nu waar gebeurd is of niet, doet er niet zoveel toe. Het illustreert wel het gevaar van het fitten van een model zonder dat je op een of andere manier kunt controleren dat je ook echt meet wat je wil meten.
Zou het niet zo kunnen zijn dat er met de uitspraken van Armstrong net zoiets aan de hand is? Ik kan wel wat suggesties daarvoor geven. In het radio-interview stelt Postma dat het programma vooral bij de uitspraken die over medewerkers gingen (dokters, ploegmaten) aangeeft dat er twijfel is over het waarheidsgehalte. Over die uitlatingen is waarschijnlijk heel goed van te voren nagedacht door Armstrong en zijn begeleiders, bijvoorbeeld vanwege de juridische consequenties. Dit geeft Postma ook wel aan, maar trekt niet de conclusie dat dat (die intensieve voorbereiding) misschien wel het onderscheid is dat je meet, in plaats van het liegen of waarheid spreken.
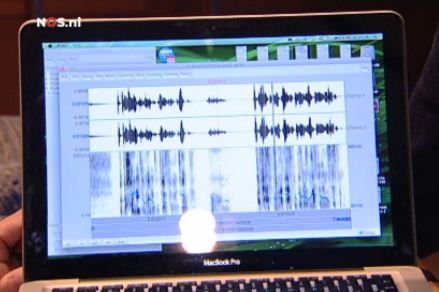
Stemanalyse
Overigens werd niet alleen die gezichtsanalyse gebruikt, ook de stem werd geanalyseerd. Armstrong zou in zijn dubieuze uitspraken met een hogere toon en andere snelheid hebben gesproken. Dit kan wijzen op een grotere spanning en dus(?) wijzen op leugenachtigheid. Maar conclusies trekken over het waarheidsgehalte van uitspraken op grond van dit soort stemanalyses, is wetenschappelijk gezien zeer omstreden.
De combinatie van metingen aan het gezicht met de stemanalyse kan misschien een meer betrouwbaar systeem opleveren. De onderzoekers wijzen onder andere op een studie (van Elkins, Derrick en Gariup) die vorig jaar gepresenteerd is op een congres: “The Voice and Eye Gaze Behavior of an Imposter: Automated Interviewing and Detection for Rapid Screening at the Border“ (pdf). Daar werd een ogenschijnlijk indrukwekkend resultaat behaalt: 100% van de ‘imposters’ werd gedetecteerd en slechts twee onschuldigen werden verkeerd ingedeeld. Hier gaat het echter om een strikt protocol dat de proefpersonen moeten doorlopen en ook de data waarover gelogen kan worden (gegevens op een visa) zijn vooraf heel precies bekend. In zo’n kunstmatige situatie is het mijns inziens meer voor de hand liggend dat je kunt uitgaan van een vergelijking waarin het enige echte verschil zit in het al dan niet de waarheid spreken.
Rijp voor de media?
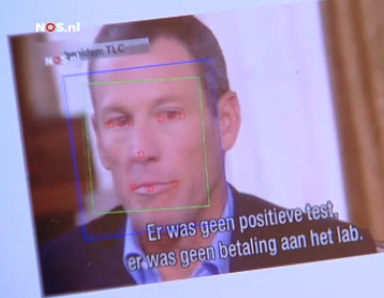
De uitspraak dat een computerprogramma, ontwikkeld door wetenschappers, zou laten zien dat een specifieke uitspraak met 80 procent kans gelogen is, krijgt zoals die gebracht is in het NOS journaal meer gewicht dan je zou wensen. In andere media werd het verhaal al een stuk minder genuanceerd doorverteld (voorbeeld) en dat lijkt me geen goede zaak. Impliciet stel je namelijk ook dat anderen die bij de ‘deal’ betrokken zouden zijn, of er van hebben moeten geweten (o.a. Hein Verbruggen en Pat McQuaid van de UCI), op dit punt altijd hebben gelogen. En dat zonder die personen aan een vergelijkbare analyse te onderwerpen. Het lijkt inmiddels wel duidelijk dat zij al die jaren veel meer van dopinggebruik wisten dan ze verteld hebben, maar het is maar zeer de vraag of ze in deze specifieke kwestie hebben gelogen.
Het is wel grappig dat Armstrong enige tijd vóór zijn bekentenissen bij Oprah aangaf, bereid te zijn om verklaringen af te leggen onder controle van een leugendetector. Maar alléén als de getuigen die hem beschuldigd hadden ook aan zo’n test zouden worden onderworpen. Misschien begreep hij al donders goed dat je met het testen van zoveel personen op één feit niet snel een heel duidelijk te interpreteren resultaat zult krijgen.
De onderzoekers zijn van plan de studie en bevindingen op papier te zetten en tegen die tijd zal ik er misschien wel eens op terugkomen. Vooralsnog ben ik niet overtuigd dat deze vorm van leugendetectie ooit betrouwbaar genoeg zal zijn om in serieuze zaken toe te passen. Het is mij teveel een ‘black box’ en het is erg lastig om uit te sluiten dat je model niet iets anders meet dan je denkt. De problematiek is enigszins vergelijkbaar met hoe er met fMRI-scans wordt omgegaan (zie mijn blog over het misplaatste optimisme over de Pedoscan). Ook het gegeven dat het een persoons specifieke analyse is en dat het niet bij iedereen werkt, doet mij twijfelen aan de robuustheid van de systeem. Sommige mensen zijn dus in staat om, al dan niet bewust, de tekenen die zouden moeten wijzen op leugenachtigheid te verbergen. Wat zegt dat over de betrouwbaarheid van de waardering van losse uitspraken van personen waarbij het systeem dat verschil wel lijkt te kunnen aanwijzen?
In ieder geval lijkt het me niet zo slim om het in handen te geven van overenthousiaste sportverslaggevers (‘Geweldig apparaat!‘). Maar aan de andere kant gaat het neersabelen van het onderzoek zonder de details te kennen (‘De nieuwe Diederik Stapel!‘) mij weer veel te ver. Minister Opstelten doet er echter vooralsnog verstandig aan om leugendetectie in het lijstje Onorthodoxe Opsporingsmethoden te laten staan, naast de paragnosten en hypnose.
Steun Kloptdatwel
 Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
Waardeer je dit artikel? Je kunt onze site steunen met een financiële bijdrage. Dat waarderen wij dan weer! Een donatie kun je doen via dit betaalverzoek (of klik op de afbeelding hiernaast).
NB de rekening staat op naam van Maarten Koller, formeel eigenaar van deze site.
Het klinkt wel mooi, 80% kans dat hij liegt. Maar wat wil dat zeggen? 80% kans is ook ongeveer de kans om met twee dobbelstenen minstens 5 te gooien. Wat is voor de professor het risico? Stel je even voor dat iemand in een pokerbeker twee dobbelstenen schudt en de beker omgekeerd op tafel zet. De professor zegt ‘er is 80,6% kans dat het puntentotaal ten minste 5 is’.
Dat is de uitkomst van een correcte berekening. Maar als voorspelling van het puntenaantal is het waardeloos. Want stel eens dat de professor zou weten dat hij oneervol ontslagen zou worden als charlatan, wanneer bij het optillen van de beker zou blijken dat er dubbeltwee ligt (of een-drie of dubbel-een). Dat weegt niet op tegen de roem als ‘knappe kop die op de teevee geweest is’ wanneer het puntenaantal wel vijf of meer is.
Er zijn verschillen tussen het pokerspelletje van zonet en de leugendetector van de professor. In de eerste plaats is het volstrekt niet zeker dat de berekening klopt. In de tweede plaats kan niemand makkelijk nagaan of Lance A. nu echt gelogen heeft heeft of niet. En last but not least loopt de professor geen enkel risico. Als het niet uitkomt (gesteld dat we er ooit achter komen), kan hij makkelijk zijn schouders ophalen en zeggen ‘tja, er was 20% dat hij toch de waarheid sprak’.
Maar als een willekeurige waarzegger met een vooroordeel of voor mijn part iemand die door het opgooien van een munt tot zo’n uitspraak komt, dan snelt de NOS daar niet naar toe om de wetenschappelijk gevalideerde parelen der wijsheid vast te leggen. Is er enig solide bewijs dat de methode van de professor in de praktijk beter is dan een munt opgooien? En sinds wanneer telt “80% zeker” eigenlijk als voldoende zeker voor het onderbouwen van beschuldigingen? De rechtspraak gaat uit van vrijwel absolute zekerheid. Dat is natuurlijk een fictie uit de tijd dat verklaringen onder ede van meerdere ooggetuigen, dan wel een ambstedige verklaring van één getuige, of gewoon zelfs alleen maar een bekentenis, verondersteld werden zulk een zekerheid te scheppen. Het beginsel dat je grote zekerheid hoort te hebben bij beschuldigingen van personen blijft.
[ En sinds wanneer telt “80% zeker” eigenlijk als voldoende zeker ..]
Dat was ook mijn eerste reactie toen ik het artikel las. Hier wreekt zich de afwezigheid van een wetenschapsredacteur bij de NOS:
NOS gaat de mist in met bericht over straling
http://www.denieuwereporter.nl/2013/01/zo-ging-de-nos-opnieuw-de-mist-in-met-wetenschapsnieuws/
Wetenschappers bezoeken NOS
http://www.wetenschapsjournalisten.nl/vwn/index.php?option=com_content&view=article&id=780:verslag-bezoek-nos-redactie-&catid=39:verslagen&Itemid=91
Misschien wil Heleen Dupuis wel iets zeggen over het ethische aspect van iemand van liegen beschuldigen met slechts 80% zekerheid.
Ik heb er 83,3 % uitgerekend. 30 goede op de 36 mogelijke.
Jan Willem wilde ons vast even testen op onze oplettendheid 😉
Nee hoor, ik heb me gewoon verteld.
Dat doen wel meer skeptici. 😉 Het is mooi dat jij het toegeeft.
Denk jij dat het interview dat NOS in een uitzending laat zien het hele verhaal is?
Kan een professor er iets aan doen dat alleen de fragmenten die goed scoren in het journaal komen?
[deel verwijderd door Mod(PvE): ongepast]
Natuurlijk is niet alles uitgezonden, maar in mijn correspondentie met Postma is door hem niet naar voren gebracht dat het daardoor verdraaid is. Hij heeft gewoon gesteld dat Armstrong (volgens de systematiek met stem en gezichtsanalyse) op dat ene punt met 80% kans heeft gelogen.