Hieronder staat de documentaire ‘The Joy of Stats’. Omdat statistiek belangrijk is en je er best van kan genieten.
Met dank aan Jan Verhoeven voor de tip.
Sinds enige tijd schrijft Victor Lamme, hoogleraar Cognitieve Neurowetenschap aan de Universiteit van Amsterdam, columns in de krant nrc.next. Op 16 maart publiceerde hij er een met de titel ‘De pedoscan‘. Die is gewijd aan het onderzoek van Jorge Ponseti waarin die bekijkt of je met hersenscans onderscheid kunt maken tussen pedofielen en ‘normale’ mensen. Opmerkelijke conclusie van dat onderzoek is dat dat vrij precies mogelijk lijkt te zijn. Ponseti ontwikkelde een test waarin proefpersonen werden blootgesteld aan plaatjes van naakte volwassenen en kinderen. En door te kijken hoe verschillend de scans eruit zien, kan met een hoop rekenwerk ‘bepaald’ worden of iemand pedofiel dan wel ‘normaal’ is. Maar dit soort rekenpartijen op basis van meetgegevens hebben toch altijd te maken met marges, fout-positieven en dat soort statistische kanttekeningen? Hoe zit het daar mee? Victor Lamme trekt in ieder geval niet de goede conclusies uit het gecijfer. Een 100 procent betrouwbare pedoscan ligt nog niet om de hoek.

Bij zo’n beetje elke test die twee uitslagen geeft, positief of negatief, heb je naast de correcte (positieve en negatieve) uitslagen ook fout-negatieve en fout-positieve uitslagen. Een fout-negatieve uitslag wil zeggen dat je test de eigenschap niet aanwijst, terwijl die er in werkelijkheid wel is. Een fout-positieve uitslag is net andersom: de eigenschap wordt ten onrechte aangetoond door de test.
Nu wil je graag dat een test zo weinig mogelijk fout-negatieve resultaten geeft, dat heb je een hoge sensitiviteit, maar ook zo weinig mogelijk fout-positieve, een hoge specificiteit. Meestal is het lastig om zowel de sensitiviteit als de specificiteit heel hoog te krijgen. Vooral in juridische aangelegenheden is een hoge specificiteit van belang, je wil immers niet mensen ten onrechte beschuldigen.
Hoe betrouwbaar is de ‘pedoscan’?
De resultaten van Ponseti zijn zo mooi, omdat zijn test de hersenscans van de 32 ‘normale’ proefpersonen allemaal als ‘normaal’ herkende, een specificiteit van 100 procent! Op de sensitiveit moet dan wel wat ingeleverd worden, want van de 24 pedofielen, werden er 3 niet juist geïdentificeerd. De sensitiviteit is dus 21/24 = 88 procent, afgerond. Lamme legt uit waarom het zo belangrijk is, dat het niet net andersom is:
Pedofilie is gelukkig zeldzaam. Precieze getallen zijn er niet, schattingen lopen uiteen van 0,1 procent tot 4 procent. Laten we uitgaan van 1 procent. Als je dan 1.000 mannen scant zijn er 10 pedofiel. Stel nu eens dat de specificiteit 88 procent was, en de sensitiviteit 100 procent (dus dat er nooit een pedofiel wordt gemist). Dan zou je alle 10 pedofielen eruit vissen, maar tegelijk ook 120 mannen ten onrechte beschuldigen (12 procent van die 1.000). Met de door Ponseti behaalde specificiteit van 100 procent beschuldig je nooit een man ten onrechte, maar haal je wel 9 van de 10 pedofielen eruit. Tot zover de wiskunde.

Tsja, tot zover gaat misschien de wiskunde van Victor Lamme. En dat is wel een beetje gênant, want het geeft een volstrekt verkeerd beeld. De specificiteit van de test van Ponseti is de uitkomst van een steekproef en is hooguit de beste schatting van de ‘echte’ specificiteit. Je kunt niet uit het feit dat geen van de 32 gezonde proefpersonen als pedofiel word aangewezen, afleiden dat de specificiteit precies 100 procent is.
Het is eenvoudig in te zien dat je net zo goed kunt stellen dat die specificiteit bijvoorbeeld maar 95 procent is (één op twintig is dan fout-positief). Ook dan is de kans behoorlijk groot dat je de 32 mannen in het goede vakje plaatst. Die kans is gelijk aan het niet gooien van ’20’ in 32 beurten met een dobbelsteen met 20 vlakken: ongeveer 19 procent (0,95 tot de macht 32). Een kleine kanttekening moet ik hierbij wel maken, je gaat er dan van uit dat er wel een zekere spreiding in de gemeten waarden is. Maar dat blijkt wel uit het vervolg.
Wil je preciezer berekenen wat die specificiteit voor waarden kan hebben, kun je een van de vele tools op Internet gebruiken. Als je de steekproefresultaten invoert, kom je uit op een 95 procent betrouwbaarheidsinterval van 87 tot 100 procent. Dat is even wat anders dan te stellen dat Ponseti’s test geen fout-positieven kan opleveren! Er is zelfs nog een kans van één op twintig dat de specificiteit in werkelijkheid lager is dan 87 procent. [update: deze tools blijken niet zo precies in dit geval. De echte ondergrens is 91 procent. Zie de commentaren.]
Het rekenwerk van Ponseti
De valse zekerheid van het abstracte gegoochel met getallen wordt ook wat duidelijker als je bekijkt hoe die test van Ponsetti nou eigenlijk in elkaar steekt. Het artikel Assessment of Pedophilia Using Hemodynamic Brain Response to Sexual Stimuli is niet voor iedereen toegankelijk, maar ik kan er wel het een en ander over vertellen. In het onderzoek werden aan proefpersonen vier soorten blote plaatjes getoond van vrouwen, meisjes, mannen en jongens. Bij elke vertoning van een afbeelding werden fMRI-scans gemaakt. Dat levert plaatjes als hierboven op. Deze plaatjes, in feite een hele berg getallen, worden omgezet in een waarde die aan moet geven hoe opgewonden de proefpersoon is. Dit kan al op heel veel verschillende manieren, die je met een ander soort meting (die ook onnauwkeurigheden heeft) moet toetsen. Vervolgens worden er per proefpersoon twee uitkomstwaarden berekend, namelijk het verschil in opwinding bij het zien van vrouwen ten opzichte van meisjes en het verschil tussen het zien van mannen en jongens. Met die waarden kun je alle proefpersonen in een grafiekje zetten.
De test die Ponseti nu eigenlijk heeft bedacht, bestaat voor het belangrijkste deel in het bepalen van een verdeling van het vlak van de grafiek in twee delen. De verdeling moet zodanig zijn dat in het ‘goede’ stuk alle ‘normale’ personen vallen en in het ‘foute’ gebied zoveel mogelijk pedofielen.
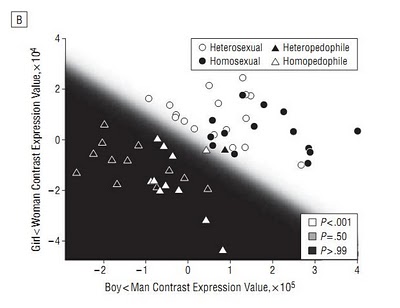
In het plaatje hiernaast is dat duidelijk gemaakt. De rondjes zijn de ‘normale’ mannen die meededen. Zij vallen allemaal in het goede, witte, gebied. Er zijn een paar pedofielen, de driehoekjes, die er echter ook in vallen. Dat zijn de fout-negatieven.
Je kunt (en moet) je afvragen of deze verdeling niet heel erg afgestemd is op deze 56 deelnemers aan het onderzoek, of andere verdelingen niet net zo goed zouden zijn. Dat doen de onderzoekers gelukkig ook wel een beetje en ze deden een zogenaamde ‘leave-one-out crossvalidation‘. Je laat dan telkens één persoon uit de dataset, doet opnieuw de verschillende splitsingen in zwart en wit in de grafiek en kijkt of de weggelaten persoon in het goede vlak zou vallen. De beste methode bleek deze simpele lineaire verdeling te zijn.
Het is dus ook helemaal niet zo dat er van tevoren een test bedacht is, die in het onderzoek zo bleek uit te pakken dat die een specificiteit van 100 procent geeft. Nee, de test is achteraf zo afgesteld dat die in ieder geval die specificiteit geeft. Het bijzondere is alleen dat je dan nog zo’n hoge sensitiviteit overhoudt.
Mooie oplossing, of niet?
Allemaal leuk en aardig, maar waar zijn we nu eigenlijk helemaal mee bezig? Is het resultaat wel generaliseerbaar naar de gehele populatie? Die 24 pedofielen zijn misschien wel helemaal niet representatief voor alle pedofielen, die we zouden willen testen. Deze waren namelijk allemaal al ‘uit de kast gekomen’ en zaten in programma’s om om te leren gaan met hun pedofilie.
Dat is één probleem, maar er zijn ook fundamentele twijfels aan de waarde van dit rekenwerk op basis van fMRI-scans. Bert Keizer stelt in een stuk in Trouw zeer terecht de vraag of we wel kúnnen weten wat we meten met zo’n hersenscan en wat voor conclusies we mogen trekken op basis daarvan:
Stel dat een pedofiel van wie we het niet vermoeden, maar die voor deze test gescreend wordt, bij het zien van pedoplaatjes helemaal geen plezier beleeft, maar zich schaamt? Precies dezelfde schaamte die, plaatsvervangend, wordt gevoeld door de hetero die ernaar kijkt. Wat zeggen we als Robert M. brandschoon blijkt op zo’n scan? Dat hij eigenlijk niks gedaan heeft? De drogreden blijft dat je op basis van een scan precies weet wat er door iemand heen gaat én dat je op grond daarvan gedrag kunt voorspellen.
Victor Lamme geeft in zijn column niet alleen een verkeerde weergave van de betrouwbaarheid van de ‘pedoscan’ maar verwacht er ook veel te veel van:
Was het Amsterdamse drama dat Robert M. heeft aangericht hiermee voorkomen? Het lijkt me dat een pedofiel niet eens gaat solliciteren als hij weet dat er van zijn brein een dergelijke scan wordt gemaakt. Een crèche kan zich mooi onderscheiden in de nu zo moeilijke markt voor kinderopvang: ‘onze medewerkers zijn pedoscanproof!’
Het kan best zo zijn dat pedofielen minder zullen solliciteren naar functies in de kinderopvang als dit soort detectie ingang vindt. Maar dat maakt de kans alleen maar groter dat iemand die wel solliciteert en positief uit de test komt, geen pedofiel is. En de term ‘pedoscanproof’ wekt, bij mij in ieder geval, eerder de suggestie dat er geen fout-negatieven zouden voorkomen. En die zijn er dus juist wel met de test van Ponseti. Ook is er onderzoek dat aantoont dat soortgelijke tests die gebruikt worden voor leugendetectie, te foppen zijn.
De valse zekerheid van dit soort testen zal hopelijk niet zo gaan uitpakken, dat we begeleiders in de kinderopvang die ‘slagen’ voor de test blindelings gaan vertrouwen. En dat we zeer verstandige maatregelen, zoals minstens twee begeleiders tegelijkertijd op een groep, overboord gaan gooien, omdat je dan kunt bezuinigen in deze ‘nu zo moeilijke markt voor kinderopvang‘.
Een paar andere artikelen over het onderzoek van Ponseti:
Een recent onderzoek kwam met een opmerkelijke conclusie: er zou een verband zijn tussen de emotionele waardering van woorden en de positie van de letters van die woorden op het QWERTY-toetsenbord. Kort samengevat: hoe meer letters van een woord aan de rechterkant van het toetsenbord zijn te vinden des te positiever wordt het woord gezien. En niet alleen in het Engels, maar ook in het Spaans en Nederlands! Als het in drie talen optreedt, kan het haast geen toeval meer zijn, toch? Of missen de onderzoekers wat alternatieve verklaringen?
 De onderzoekers Kyle Jasmin en Daniel Casasanto publiceerden in Psychonomic Bulletin & Review een artikel getiteld The QWERTY Effect: How typing shapes the meanings of words (vrij toegankelijk). Het resultaat is opvallend en het verwondert me niet dat het op allerlei websites met (populair) wetenschappelijk nieuws werd vermeld (Nederlandse sites: scientias, KIJK).
De onderzoekers Kyle Jasmin en Daniel Casasanto publiceerden in Psychonomic Bulletin & Review een artikel getiteld The QWERTY Effect: How typing shapes the meanings of words (vrij toegankelijk). Het resultaat is opvallend en het verwondert me niet dat het op allerlei websites met (populair) wetenschappelijk nieuws werd vermeld (Nederlandse sites: scientias, KIJK).
Wired sprak ook met een van de auteurs, Jasmin, en dat artikel lijkt voor veel andere publicaties weer de belangrijkste bron. Veel van de commentaren bij het Wired-artikel zijn sceptisch: gaat het hier niet om een toevallig resultaat, datafitting of iets dergelijks? Jasmin brengt daar in een commentaar tegen in dat dat bijna uitgesloten is, omdat het in alle drie de onderzochte talen optreedt:
The trend is there, demonstrated in 5 large corpora of words, which included 3 different languages. The balance of right-side and left-side letters in a word was a strong predictor of the word’s emotional valence. For every letter you add that tips the scale to the right, you get, on average, about a 4% boost in positive valence. With respect to ‘proven’ or ‘not proven’, we predicted an effect and replicated it several times — it is statistically very unlikely to be a fluke.
Wat is het verband nu precies?
De onderzoekers gebruikten een standaard Engels woordenlijst die is verrijkt met emotionele waarderingen op een 9-puntsschaal (9 heel positief, 1 heel negatief). Deze ANEW lijst heeft een Spaans (SPANEW) en Nederlands equivalent (DANEW), die gebaseerd zijn op vertalingen van de Engelse lijst en opnieuw gewaardeerd door Spaans- en Nederlandstaligen. Vervolgens definiëren de onderzoekers een score per woord die aangeeft hoe de verhouding is tussen de ‘linkse’ en ‘rechtse’ letters op het QWERTY-toetsenbord. Ze noemen die RSA (right-side advantage) en je berekent die door het totaal aantal rechtse letters (y, u, i, o, p, h, j, k, l, n, m) te verminderen met het totaal aantal linkse letters (q, w, e, r, t, a, s, d, f, g, z, x, c, y, b). Voor een woord als ‘aangenaam’ wordt de RSA dan -1-1+1-1-1+1-1-1+1 = -3.
Nu kun je kijken naar het verband tussen de RSA en de emotionele score, waarvoor ik verder de Engelse term ‘valence’ zal gebruiken zoals dat ook in het artikel gebeurt. Het volgende plaatje (uit het supplement bij het artikel, Appendix C ) laat zien wat het verband is:
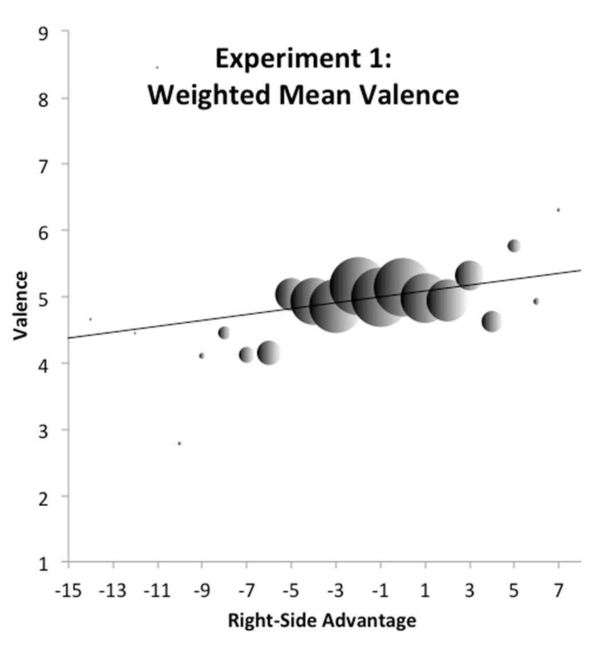
De helling van de lijn geeft het verband aan dat Jasmin in zijn quote geeft: gemiddeld geeft een stijging van een punt op de RSA-schaal een verhoging van 4% in valence. Deze grafiek is wel een beetje raar: de bollen geven het gewogen gemiddelde van de valence aan bij elke RSA. Waarom ze nu eerst dat gewogen gemiddelde bepalen en dan een regressie uitvoeren, ontgaat me een beetje. In een eerdere publicatie deden ze dat niet en zagen de plaatjes er wat chaotischer uit, maar in feite bevatten ze dezelfde informatie. Voor velen zal nu het verband er veel minder overtuigend uit zien.
De verklaring van Jasmin en Casasanto
De auteurs beweren dat het typen van ‘linkse’ letters lastiger is. Aan de linkerzijde heb je immers meer letters om uit te kiezen, wat meer moeite kost. En woorden die veel ‘linkse’ letters bevatten en aldus lastiger te typen zijn, zouden daarom ook minder positief gewaardeerd worden. In de woorden van Jasmin:
As we filter language, hundreds or thousands of words, through our fingers, we seem to be connecting the meanings of the words with the physical way they’re typed on the keyboard. If it’s easy, it tends to lend a positive meaning. If it’s harder, it can go the other way.
Natuurlijk stellen de onderzoekers dat het effect beperkt is, de betekenis van de woorden is nog altijd de belangrijkste factor die de valence bepaalt. Het klinkt nogal vergezocht, maar Jasmin stelt dat ook bekend is dat de manier waarop woorden worden uitgesproken een dergelijk invloed heeft op de betekenis van die woorden.
Is het niet gewoon toeval?
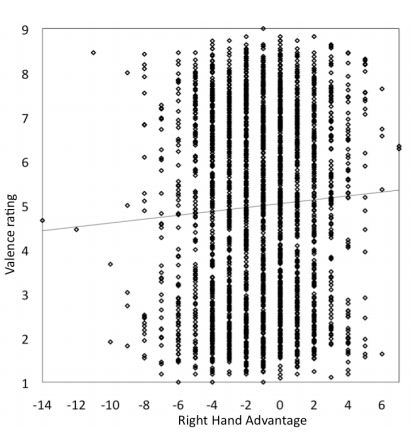
Het verband is sowieso niet al te sterk (de lijn in de grafiek loopt niet zo steil) en het zou aan de toevallige selectie van woorden in ANEW kunnen liggen (het gaat om 1043 woorden). Mark Liberman onderzocht het ook in een blog op language log. Hij deed de analyse zelf voor de ANEW en DANEW lijsten apart en dat leverde vergelijkbare grafieken op, maar het effect is dan niet significant. Dat wordt het blijkbaar pas als je de drie lijsten bij elkaar gooit op één hoop. Liberman gooide ook drie keer de koppeling tussen RSA en valence willekeurig door elkaar (met de ANEW lijst) om te kijken of het toevallig kan optreden. Hij vond één keer ongeveer hetzelfde positieve verband, één keer eerder een negatief effect en één keer geen relatie. Het zou op die gronden alleen al toeval kunnen zijn.
[update 19-3-2012] Er is intussen een discussie tussen Liberman en de auteurs gaande over onder andere de significantie. Casasanto en Jasmin hebben een officiële reactie op de kritiek op Language Log geschreven, die ook een aantal zaken in het artikel verduidelijkt: The Robustness of the QWERTY Effect.
Wat zou je verder kunnen analyseren?
Er zijn nog wel andere zaken die je zou moeten onderzoeken in mijn ogen. Als je naar de grafiek kijkt, lijkt het dat de helling van de grafiek voor een belangrijk deel bepaald wordt door de uitschieters. Beperk je de RSA-scores even tot het interval [-6,4] dan lijkt het me dat er nauwelijks een helling over zou blijven, dus geen positief verband. Het kan goed zijn dat een handjevol woorden relatief veel invloed heeft. Dit zijn dan woorden die redelijk lang zijn, anders kan er geen groot overschot aan linkse of rechtse letters zijn. Die langere woorden veranderen vaak in vertaling van Engels naar Nederlands of Spaans ook lang niet zo veel als kortere woorden, bijvoorbeeld “aggressive – agressief – agresivo” met RSA scores resp. -8,-7 en -4. De woordenlijsten zijn in mijn ogen dan ook niet zomaar als onafhankelijk te beschouwen.
De onderzoekers laten de koppeling tussen de vertaalde woorden helemaal los en hiermee gooien ze informatie weg (zonde!). Je zou die koppeling ook goed kunnen gebruiken om de hypothese te falsifiëren. Je verwacht namelijk dat de woorden in vertaling wel ongeveer vergelijkbaar blijven in valence, maar de RSA kan nogal verschillen. Als de hypothese klopt dat de RSA verband houdt met valence, zou je dat eigenlijk moeten terugzien bij die vertalingen. Als de vertaling een lagere RSA heeft, zou je ook verwachten dat het een lagere valence heeft. Dat zie je natuurlijk niet door naar enkele voorbeelden te kijken, maar het zou een zichtbaar verband moeten zijn als je dat voor alle woorden uit de ANEW lijst doet.
Een voorbeeldje dat aan de verwachting voldoet is “vomit”, dat heeft een RSA van +1 en een valence van 2,06. De Nederlandse vertaling “braaksel” heeft RSA -4 en valence 1,86. Maar “achievement”, met RSA -3 en valence 7,89, wordt “prestatie”, met RSA -5 en valence 8,17 en gaat dus net de andere kant op.
Het is een fluitje van cent om dit te doen voor alle woorden in de ANEW, DANEW en SPANEW lijsten. Maar toen ik de onderzoekers dit per e-mail voorstelde, kreeg ik een erg lauwe reactie. Ook op mijn vraag naar hun mening over de analyses van het language log reageerde Daniel Casasanto onverwacht. De analyses van Liberman zouden ‘nonsensical’ zijn, zonder overigens aan te geven waarom. Op dat moment wist ik niet eens dat Liberman een vooraanstaand hoogleraar is, maar was gewoon erg overtuigd van zijn argumenten in zijn blog en de commentaren erop.
Ik zou de analyse naar de invloed van de mogelijke afhankelijkheid tussen de lijsten graag zelf even doen, maar ik vond ze alleen gealfabetiseerd en de koppeling tussen origineel en vertaling zou je zelf moeten reconstrueren. Het is wel te doen, maar het kost behoorlijk wat tijd. Ik verwacht eerlijk gezegd ook niet dat het verband er uit zal komen, dus die klus ga ik vooralsnog niet op me nemen.
[update 19-3-2012] Uit de nadere toelichting van Casanato en Jasmin maak ik op dat ze de mogelijke afhankelijkheid tussen de verschillende vertalingen hebben proberen te ondervangen door in de regressie de valence van de vertalingen als ‘herhaalde waarnemingen’ in te voeren. Ik vraag me af of dit juist is, want dan ga er a-priori van uit dat de werkelijke valence in elke taal hetzelfde zou moeten zijn en dat is duidelijk niet het geval. Je zou het bij een correcte vertaling wel verwachten, maar zo simpel is het niet: als je een woord als ‘execution’ in het Nederlands vertaald als ‘uitvoering’ mis je de negatieve connotatie van ‘terechtstelling’.

Het nevenbewijs van de onderzoekers
Naast het hoofdexperiment keken de onderzoekers naar twee andere lijstjes (dat maakt samen met de drie eerder genoemde lijsten het totaal van vijf uit de quote van Jasmin). Ten eerste analyseerden ze een woordenlijst met woorden die na de ontwikkeling van het QWERTY-toetsenbord zijn ontstaan (dus na 1873). Het idee daarachter is dat je dan zou kunnen zien of met de vastlegging van de toetsenindeling ook de ontwikkeling van nieuwe woorden beïnvloed zou worden. En weer bleek hetzelfde verband.
Nu is het gebruikte lijstje van 63 woorden niet op een heel erg duidelijke manier samengesteld (zie het supplement voor de hele lijst) en overtuigt mij daarom niet echt. Veel woorden zijn populair internetjargon, niet echt ‘common knowledge’ en veel zijn ook min of meer dubbel.
Ten slotte werd er onderzocht hoe het met de valence van fantasiewoorden zit. Met een algoritme werd een lijstje woorden samengesteld en via Mechanical Turk op Internet aan proefpersonen voorgelegd. Weer eenzelfde verband. Ook dit experiment stelt in mijn ogen niet veel voor. Door de vorm van de gebruikte woorden is de lijst niet echt vergelijkbaar met een lijst ‘echte’ woorden (de variatie in woordlengte is bijvoorbeeld heel beperkt). En het zijn dan wel niet bestaande Engelse woorden, sommige komen bijvoorbeeld weer wel in het Nederlands voor. Belangrijker is echter de vraag of het gevoel bij een niet-bestaand woord wel vergeleken kan worden met het gevoel van een woord waarvan de betekenis bekend verondersteld mag worden.
Kortom: als er al sprake is van een QWERTY-effect, dan overtuigt deze studie mij daar niet van. Misschien dat de onderzoekers in een vervolg meteen ook even de invloed van de kleur van de tekst mee kunnen nemen, of het lettertype?

Ken je het negenpuntenprobleem? Dat raadsel waarbij negen punten in een 3×3-patroon worden opgesteld en door slechts 4 rechte lijnen met elkaar moeten worden verbonden zonder dat je je pen optilt? De oplossing is alleen mogelijk door buiten de voor de hand liggende denkpatronen te treden. Klik niet direct op de link, probeer het eerst zelf maar ‘s.
De manga-strip “Liar Game” bevat veel van dat soort raadsels. Het zijn bijna allemaal cijferproblemen.
Het verhaal begint als het hoofdpersonage Nao 100 miljoen krijgt van de organisatie van een spel. Dat spel is eenvoudig: de deelnemers mogen die 100 miljoen van elkaar stelen. Maar als het spel voorbij is, moet je het geld dat je van de organisatie kreeg, wel volledig teruggeven. Wat van je is gestolen, heb je dan als schuld bij de organisatie. Nao is iemand die “te goed is voor deze wereld”. en er dus moeilijk toe kan komen het geld van de anderen in te pikken. Ze probeert dus alleen maar om zelf geen geld te verliezen en zonder schulden uit het spel te stappen.
Een eenvoudig uitgangspunt, maar het spel blijft niet eenvoudig. En daardoor wordt het plots een interessante oefening in skepticisme.
Het thema van Liar Game is dat mensen in de val worden gelokt door raadsels die ze verkeerd interpreteren. De derde aflevering biedt het duidelijkste voorbeeld.
Twee spelers, twee spelkaarten. Op één kaart staat een joker. De andere is een misdruk en bevat op beide kanten een achterkant. Elke speler gokt op een van de twee kaarten. Beide kaarten worden in een zak gestoken. Het slachtoffer mag telkens een kaart kiezen.
De truc is dat de bedrieger het slachtoffer laat geloven dat ze allebei evenveel kans hebben als ze gokken op een van de kaarten. Er zijn immers maar twee verschillende kaarten. Op het eerste gezicht heeft iedereen dus 50% kans dat zijn kaart wordt getrokken.
Maar dat is niet zo.
Wie een beetje nadenkt, snapt snel waarom, en als je de strip leest, kun je het door krijgen vóór de auteur de oplossing geeft. Maar al zullen de meesten wel inzien dat Nao in de val wordt gelokt (want het is weer Nao die de dupe is), toch zullen er maar weinigen de echte finesses inzien. Een eerste redenering is dat de bedrieger de indruk wekt dat er maar twee kaarten zijn, maar daarbij verzwijgt dat er natuurlijk vier kanten zijn. Met andere woorden: wie de joker kiest, heeft al automatisch minder kans dan wie de achterkant kiest, want in werkelijkheid is er maar één joker tegenover drie achterkanten. Dus de achterkant heeft 75% kans om getrokken te worden, en de joker 25%.

Maar dat is natuurlijk een beetje te simpel. Als de kaart uit de zak wordt getrokken, ligt automatisch één zijde naar boven. Dus geldt de gok alleen als een kaart met de achterkant naar boven uit de zak wordt getrokken. Als ze met de voorkant bovenaan uit de zak wordt getrokken, is de ronde ongeldig, en gaat de kaart terug in de zak. Op die manier lijkt het spel eerlijk te zijn opgesteld. En toch is ook dat niet waar. Maar dat zullen jullie wel al hebben gemerkt.
Het interessante is nu de kansverdeling: die blijkt nog altijd in het voordeel van de achterkant te zijn, want die heeft in werkelijkheid twee kansen op drie om te worden getrokken, terwijl de joker maar één kans op drie heeft. Een gedetailleerdere uitleg staat in Liar Game III. Ik kan die niet volledig overnemen doordat er ook illustraties zijn. Het personage dat Nao uit de problemen helpt, Akiyama, doet alles precies uit de doeken.
De strip is niet bedoeld als skeptische cursus, maar toont wel hoe misleidend aannames kunnen zijn, zelfs al lijken ze nog zo logisch. Eigenlijk zit Liar Game daardoor tjokvol voorbeelden van misleidende redeneringen, uitgangspunten en veronderstellingen. De redding van het slachtoffer is de ontluistering van de aard van het bedrog, dus de verklaring waarom het slachtoffer verkeerd heeft geredeneerd.
Voor skeptici is het leuke ontspanning. De uitweg wordt altijd geboden door van de gebaande paden af te wijken.
“Liar Game III” door Shinobu Kaitani, 2011, Antwerpen (België), Kana – Ballon Media, uit de reeks “Liar Game”, oorspronkelijk “Liar Game”, 2005, Tokio (Japan), Shueisha inc., vertaling: NT Entertainment nv, Deurne in samenwerking met Taal & Teken, Schoten en Leonoor Soet, Nuenen, 200 p’s, 18×13 cm, paperback met omslag, ISBN 978-90-6334-879-3, prijs 8,50 euro
Via onderstaande link kunt u het stripboek bij Bol.com bestellen. Daarmee steunt u Kloptdatwel.
Vandaag precies één jaar, één week en één dag geleden schreef ik het eerste artikel voor Kloptdatwel. Daarom vind ik het, na minimaal één blogartikel per dag, de meeste geschreven door Gert Jan van ‘t Land en mij, weleens tijd om iets te schrijven over het hoe en waarom van onze website, waar we inmiddels best een beetje trots op zijn geworden. We hopen dat al onze lezers en deelnemers aan discussies ook een beetje trots zijn. We vinden het heel belangrijk dat het blog een levendig platform is geworden met discussie en reacties. Want het zijn toch vooral de lezers en de reageerders die Kloptdatwel tot een succes hebben gemaakt!
“Kloptdatwel”, riep iemand tijdens een bijeenkomst van de Skepsiswerkgroep 1 van Utrecht. Iedereen vond het meteen een leuke naam. We waren inmiddels al een tijdje aan het spelen met het idee om als werkgroep een eigen website op te richten. We hadden wel vaker ideeën voor artikeltjes die niet geschikt waren voor Skepsis.nl, het Skepsisblog of de Skepter terwijl we wél het idee hadden dat er een doelgroep voor te vinden zou zijn. De diepgang en hoge kwaliteit van de genoemde media was voor ons ook niet altijd haalbaar en we hadden een site voor ogen die met kortere, ludiekere en wat luchtigere stukken zou kunnen prikkelen om de langere stukken van Skepsis/Skepter te lezen. Daarnaast zou het voor schrijvers misschien wel kunnen dienen als opstapje; klein beginnen en later groter ‘eindigen’ in de Skepter.
Ons doel zoals we het toen formuleerden:
Het doel is een skeptisch platform creëren waarbij oog is voor allerlei onderwerpen die in ‘het’ skeptische wereldje voorbij komen. Zowel nationaal als internationaal. Regelmatig zal er voor meer informatie gelinkt worden naar de site van Skepsis.nl (of naar een andere gerelateerde site).
Dat is denk ik aardig gelukt.
Op Kloptdatwel.nl hebben we inmiddels ruim 380 blogartikelen gepubliceerd. Veel werk, maar ontzettend leuk om te doen. De meeste artikelen zijn geschreven door Gert Jan van ‘t Land en ondergetekende. Daarnaast hebben enkele enthousiaste werkgroepleden en ook enkele gastschrijvers zich ingezet om artikelen te schrijven, die samen meer dan 50 artikelen voor hun rekening hebben genomen. Kloptdatwel die-hards Agnes Tieben en Rosalinde van Wijck willen we met 17, respectievelijk 13 artikelen speciaal bedanken. Daarnaast willen we ook Jan Willem Nienhuys speciaal bedanken, hij houdt zich al bijna sinds het begin onvermoeibaar bezig met tekst- en soms stijlcorrectie. Gert Jan en ik verdelen een aantal werkzaamheden die je moet uitvoeren om van Kloptdatwel iets moois te maken, zoals bijvoorbeeld techniek, vormgeving, ons beleid t.a.v. reacties, PR en de redactie van stukken. Dat betekent regelmatig contact, vaak na de werkdag (en soms laat).
Aantal bezoekers
De belangrijkste succesfactor zijn natuurlijk niet de stukjes maar de bezoekers en de discussie. Het aantal bezoekers is opgelopen vanaf de start. De eerste maand sinds oprichting hadden we ongeveer 3 – 16 unieke bezoekers per dag. Na het Skepsis congres 2010 steeg het aantal snel en sindsdien is zijn de aantallen gestaag toegenomen. De afgelopen 30 dagen hadden we gemiddeld 362 unieke bezoekers per dag (ongeveer 7800 per maand).
Klik op de afbeelding voor uitgebreide statistieken. De pieken hadden over het algemeen duidelijke redenen, ik heb de belangrijkste in de afbeelding beschreven.

Verder hebben we inmiddels 149 volgers op Twitter en 90 mensen hebben ons op Facebook ‘ge-Like-d’.
De stukken leiden tot discussie en dat is voor alle bezoekers relevant en interessant. Dank voor alle reacties waarmee Kloptdatwel levend is en blijft.
Steun
Behalve op de Google Ads klikken en via onze link (rechts) bij Bol.com iets bestellen zijn er natuurlijk nog meer methoden om ons te steunen.

Toekomst
We horen hier en daar geluiden dat men ons shirt zou willen aanschaffen. We zullen daar (en andere merchandise) eens over nadenken. Het zal er net iets anders uitzien dan de het shirt op de foto, want die is natuurlijk voorbehouden aan Skepsis werkgroepleden ;).
Maar er staat nog veel meer op onze wenslijst: een email nieuwsbrief, een nieuw comment systeem (mogelijk LiveFyre ipv Disqus), een redesign van de site, en vooral meer auteurs om de werkdruk te spreiden.
Kloptdatwel staat altijd open voor gastschrijvers, dus mocht je een leuk artikel willen bijdragen in de stijl en gedachtegoed van Kloptdatwel/Skepsis, mail ons dan op info@kloptdatwel.nl!